(v_18)Python Excelファイルに書き込み pandas

Excelファイルに書き込み pandas(to_excel)
PythonでExcelファイルにデータの書込みを試してみます。
記事(v_02)のBeautifulSoupでヤフー地震データを抽出を試しました。
この地震頻度データをExcelファイルに保存したいと思います。
具体的には、BeautifulSoupで得た地震頻度データをpandasでDataFrameにしてExcelファイルに保存します。
※Pythonの開発環境はThonny、実際の表計算はLibreOffice Calcを使用しています。
pandasのインストール
pandasをインストールします。
開発環境はThonnyを使用しています。そのためManage plug-insから簡単にpandasをインストールできます。
検索窓に「pandas」を入力して、右の「Search on PyPi」をクリックします。
検索結果が表示されます。一番、上の「pandas」を選択します。
「Install」をクリックします。
「pandas」がインストールされました。
Excelファイルの読み書き
ExcelファイルのデータをpandasでDataFrameで読み書きの例を示します。
■DataFrameを作る
地震頻度データはリスト型で取得するので、リストデータからDataFrameを作る例です。
ThonnyのShellで試しています。
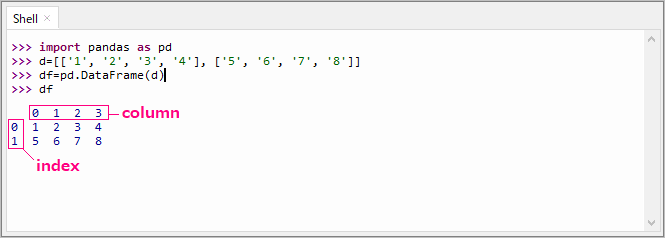
各々のリストデータは行データになっています。
>>> import pandas as pd
>>> d=[['1', '2', '3', '4'], ['5', '6', '7', '8']]
>>> df=pd.DataFrame(d)
>>> df
0 1 2 3
0 1 2 3 4
1 5 6 7 8
■カラム名の変更
[‘A’,’B’,’C’,’D’]に変更します。
>>> n_col=['A','B','C','D']
>>> df.columns=n_col
>>> df
A B C D
0 1 2 3 4
1 5 6 7 8
■Excelファイルに書き込む
このDataFrameをExcelファイル df_test.xlsx に書き込みます。拡張子は.xlsx、シート名をSheet1とします。
>>> df.to_excel('df_test.xlsx', sheet_name='Sheet1')
Thonnyのワークホルダに保存されます。
確認します。※表計算LibreOffice Calcで開いています。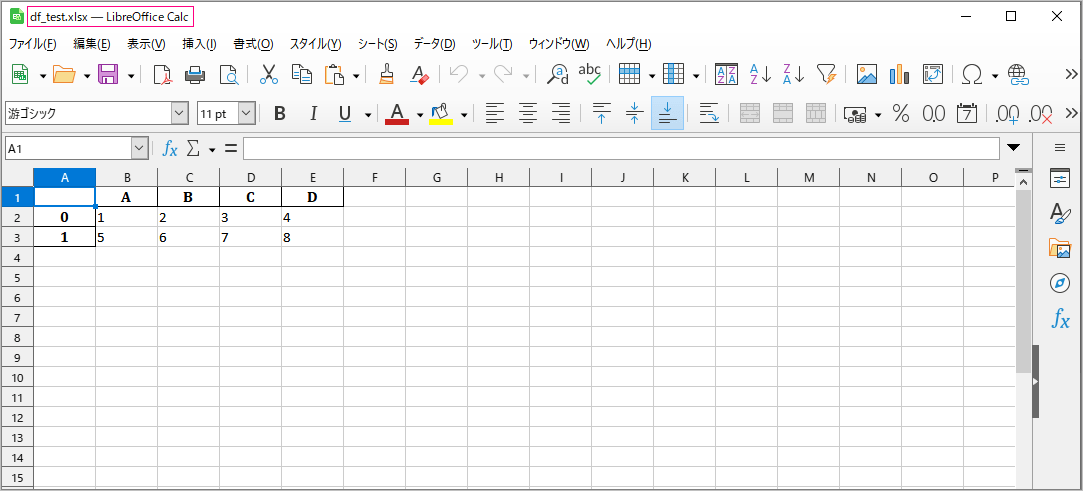
■Excelファイルの読み出し
’df_test.xlsx’カラムを[‘AA’,’BB’,’CC’,’DD’]、データを[’10’, ’20’, ’30’, ’40’], [’50’, ’60’, ’70’, ’80’]に書換えて保存し、ExcelファイルDataFrameに読み出しを試します。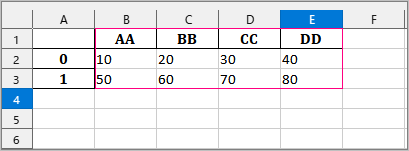
‘df_test.xlsx’の’Sheet1’をdf1に読み出します。
>>> df1=pd.read_excel('df_test.xlsx', sheet_name='Sheet1',index_col=0)
>>> df1
AA BB CC DD
0 10 20 30 40
1 50 60 70 80
■データフレームの追加
dfの縦側(行方向)にdf1を加えてみます。
先ず、df1のカラムをdfのカラムと同じにします。dfのカラムリストを取得します。
>>> n_col=df.columns.to_list()
>>> n_col
['A', 'B', 'C', 'D']
df1のカラムを変更します。
>>> df1.columns=n_col
>>> df1
A B C D
0 10 20 30 40
1 50 60 70 80
データ縦方向(行)に追加します。
>>> df2=pd.concat([df, df1], axis=0)
>>> df2
A B C D
0 1 2 3 4
1 5 6 7 8
0 10 20 30 40
1 50 60 70 80
■インデックスのリセット
インデックスの値が重なるのでリセットします。
>>> df2=df2.reset_index(drop=True)
>>> df2
A B C D
0 1 2 3 4
1 5 6 7 8
2 10 20 30 40
3 50 60 70 80
■並び替え
インデックスの降順で並べ替えしてみます。
>>> df2.sort_index(ascending=False)
A B C D
3 50 60 70 80
2 10 20 30 40
1 5 6 7 8
0 1 2 3 4
カラム’A’の降順に並べ替えしてみます。
df2のデータ型を調べます。
>>> df2.dtypes
A object
B object
C object
D object
dtype: object
■データ型の変換
データ型’object’を’int’型に変換してから並べ替えます。
>>> df3=df2.astype(int)
>>> df3=df3.sort_values(by='A',ascending=False)
>>> df3
A B C D
3 50 60 70 80
2 10 20 30 40
1 5 6 7 8
0 1 2 3 4
df3をdf_test.xlsx に書き込みます。(上書き、元データは消える)
>>> df3.to_excel('df_test.xlsx', sheet_name='Sheet1')
‘df_test.xlsx’の確認
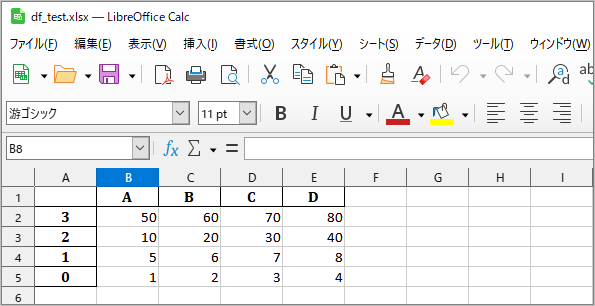
地震頻度データをExcelファイルに保存
以上を応用して、地震頻度データをExcelファイルに保存したいと思います。
ヤフー地震データから頻度データの取得は記事(v_17)にある「bs4_quake_01b.py」とほぼ同じです。
「#期間抽出」の文字列をリストで返すように変更しています。
地震頻度データを取得するスクリプトは以下のようにしました。
bs4_quake_02b.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import urllib.request
from bs4 import BeautifulSoup
import collections
#Quake Class module
class Quake:
def __init__(self,pa=10,ra=10,th=1):
self.page=pa #取得ページ数
self.rank=ra #表示上位数
self.thre=th #閾値0:震度 1:Mag
def q_Dat(self):
s=0 # <tr>数
total=0
count=0
quake=[]
place=[] # 場所だけ
for p in range(self.page):
p_val=str(p)+'01' #typhoon.yahoo page
url='https://typhoon.yahoo.co.jp/weather/jp/earthquake/list
/?sort=1&key=1&b='+p_val
req = urllib.request.Request(url)
html = urllib.request.urlopen(req)
soup = BeautifulSoup(html, "html.parser")
q_index=soup.find(id="eqhist")
# <tr>数
s=s+len(q_index.find_all('tr'))
for tr in q_index.find_all('tr'):
d_dat=[]
for td in tr.find_all('td'):
m_data=td.string
#print(m_data)
if m_data== None:
#None なら追加しない
continue
#日時、場所、マグニチュード、最大震度
#d_dat=[d_dat[0],d_dat[1],d_dat[2],d_dat[3]]
d_dat.append(m_data)
if d_dat==[]:
# 空なら追加しない 項目行が空
continue
total=total+1
#使用するデータの閾値
if self.thre==1:
# 場所d_dat[1] マグニチュー:d_dat[2] 震度:d_dat[3]
if d_dat[2]=='---' or d_dat[1]=='---':
continue
if float(d_dat[2]) < 1.5:
#マグニチュード<1.5 は除外 float(d_dat[2] < 1.5)
#震度'1'は除外 d_dat[3]=='1'
continue
else:
#震度が'1'と'---'、場所が'---'は除外する
#if d_dat[3]=='1' or d_dat[3]=='---' or d_dat[1]=='---':
if d_dat[3]=='---' or d_dat[1]=='---':
continue
#
count=count+1
if count==1:
d_st=d_dat[0] #期間抽出 最新の日時
place.append(d_dat[1]) #場所だけ
d_en=d_dat[0] #期間抽出 最古い日時
#地震Counter
c=collections.Counter(place)
self.b=c.most_common() #出現回数が多い順
if self.thre==1:
#print('閾値はマグニチュード 1.5~')
msg='閾値はマグニチュード 1.5~'
else:
#print('閾値は震度 2~')
#print('閾値は震度 1~')
msg='閾値は震度 1~'
#データ数(total)、条件内使用データ数(count)
#print(f'Data:{count}/{total}')
self.mass=f'Data:{count}/{total}'
#
#期間抽出
#self.d_dur=f'{d_st.split()[0]} ~ {d_en.split()[0]}'
self.d_dur=[d_st.split()[0],d_en.split()[0]] #[today,date]で返す
ss=''
if self.rank==0:
#print('全部表示')
self.ss=f'全部表示 '+msg
#全部データ
#print(self.b)
else:
#print(f'上位{self.rank}表示')
self.ss=f'上位{self.rank}表示 '+msg
#地震Counterデータを返す
def c_data(self):
return self.b
#データ数、ランク、文字列、データ期間を返す
def c_para(self):
return self.mass, self.rank, self.ss, self.d_dur
地震頻度データをExcelファイルに書込みます。
地震頻度の上位20まで保存することにします。
あらかじめカラムをdf_quake.xlsxに記載しておきます。
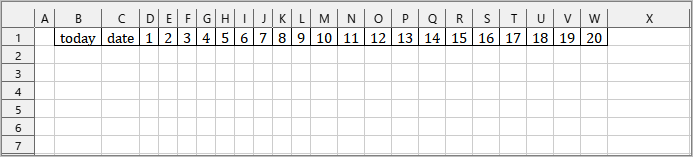
地震頻度データをExcelファイルに保存するスクリプトは以下のようにしました。
pd_excel_to_01b.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import pandas as pd
from datetime import datetime
from bs4_quake_02b import Quake
#columns Excel/file 地震頻度順位20まで
cols=['today', 'date', 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13,
14, 15, 16, 17, 18, 19, 20]
#地震頻度Excelfile df_quake.xlsx を読込
df1=pd.read_excel('df_quake.xlsx', sheet_name='Sheet1',index_col=0)
#地震頻度データ、コメントリストを取得
def y_Quake():
a=Quake(15,20,1) ##取得ページ数,表示上位数~20,閾値0:震度 1:Mag
a.q_Dat() #地震データをスクレイピング
s=a.c_data() #地震頻度データを取得
q_lst=[] #q_lstを以下のlist形式にする
#['2024年5月27日', '2024年1月17日', '石川県能登地方(283)', '能登半島沖(93)',
# 省略, 'トカラ列島近海(17)', '奄美大島近海(14)']
d_msg=a.c_para() #コメントリストを取得[データ数、ランク、文字列、データ期間]
q_lst.append(d_msg[3][0]) #today
q_lst.append(d_msg[3][1]) #date
rk=int(d_msg[1]) #上位数
for i in range(rk):
dat=s[i][0]+'('+str(s[i][1])+')' #'場所(回数)'の形に変換
q_lst.append(dat)
#print(q_lst)
#日付データをYYYY-MM-DDに変換する
def d_Dex(s_day):
d=datetime.strptime(s_day, '%Y年%m月%d日')
dd=d.strftime('%Y-%m-%d')
return dd
# list-data [0],[1]を'%Y-%m-%d'に置換する
q_lst[0]=d_Dex(q_lst[0]) #'2024年5月28日'>>'2024-05-28'
q_lst[1]=d_Dex(q_lst[1])
return q_lst
#リストデータ化する
lst=[]
lst.append(y_Quake())
print(f'地震頻度データ \n{lst}')
#地震頻度をデータフレームにする
df2=pd.DataFrame(lst)
#df2のカラム数
n_col2=len(df2.columns.to_list())
#column名を既存Excelデータのカラム名に変更
df2.columns=cols[:n_col2]
#既存データ縦方向(行)に追加
df=pd.concat([df1, df2], axis=0) #縦 行方向に追加
#日並び 降順 desc (desending) 昇順 asc (ascending)
df=df.sort_values(by=cols[0], ascending=False)
#indexをリセット
df=df.reset_index(drop=True)
#Excelファイル上書き保存
df.to_excel('df_quake.xlsx', sheet_name='Sheet1')
実行結果
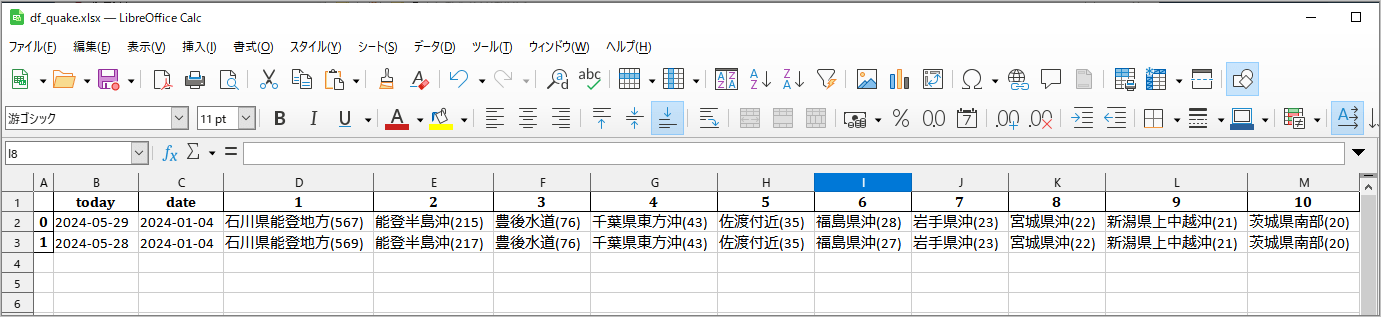
Yahooの地震データ15ページ分からマグニチュード頻度上位20までを保存した結果です。※’2024-05-28’分は先に保存しています。
>>> %Run pd_excel_to_01b.py
地震頻度データ
[['2024-05-29', '2024-01-04', '石川県能登地方(567)', '能登半島沖(214)', '豊後水道(76)',
'千葉県東方沖(43)', '佐渡付近(35)', '福島県沖(28)', '岩手県沖(23)', '宮城県沖(22)',
'茨城県南部(21)', '新潟県上中越沖(21)', 'トカラ列島近海(18)', '茨城県沖(14)',
'奄美大島近海(14)', '青森県東方沖(12)', '千葉県南部(12)', '京都府南部(11)',
'紀伊水道(10)', '熊本県熊本地方(9)', '岐阜県飛騨地方(9)', '秋田県内陸北部(9)']]
Excelファイル’df_quake.xlsx’の確認
‘2024-05-28’に追加して’2024-05-29’データをExcelファイルに保存できています。問題なさそうです。
まとめ
PythonでExcelファイルにデータの書込みを試しました。
BeautifulSoupで得た地震頻度データをpandasでDataFrameにしてExcelファイルに書込み出来ました。今後、地震頻度データを収集して行こうと思います。