(v_01)BeautifulSoup をためす

BeautifulSoup
BeautifulSoupでスクレイピングを試してみようと思います。※開発環境はThonnyを使ってます。
スクレイピング(Scraping)とは、ウェブサイトから文章などの情報を抽出することらしいです。
後で出てくるパーサ(parser)とは、何らかの言語(例えばHTML)で作成されたデータをプログラムで扱えるようなデータ構造に変換するプログラムのことらしいです。
その処理のことを「構文解析」「パース」(parse)というそうです。
よくわかりませんが、BeautifulSoupで扱うと以下のように記載します。
soup=BeautifulSoup(html, “html.parser”)
HTMLデータで作成されたウェブサイトのデータ「html」を「html.parser」の変換プログラムで構造解析した値(soup)を返す、感じになります。このsoup値をいろいろ加工して必要なデータの抽出が出来ます。
Beautiful Soup Documentationは「https://www.crummy.com/software/BeautifulSoup/bs4/doc/」にあります。
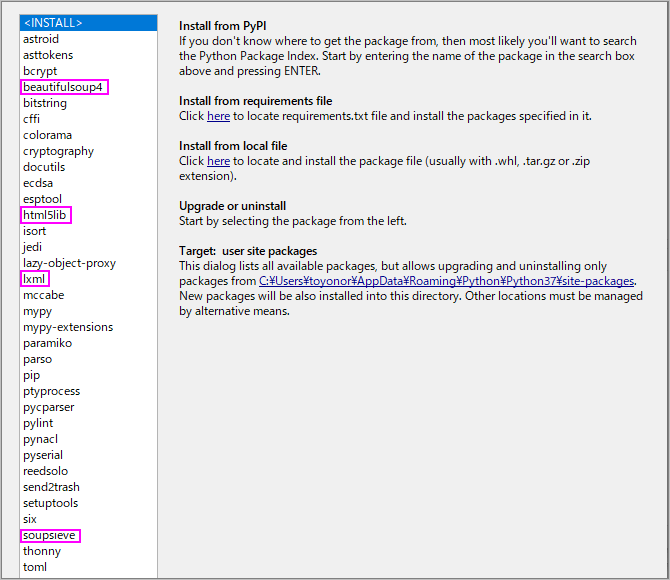
インストール
開発環境にThonnyを使用しています。
そのためManage plug-insから簡単にBeautifulSoupをインストールできます。
Thonnyのメニュー「Tool」から「Manage plug-ins…」を選択します。
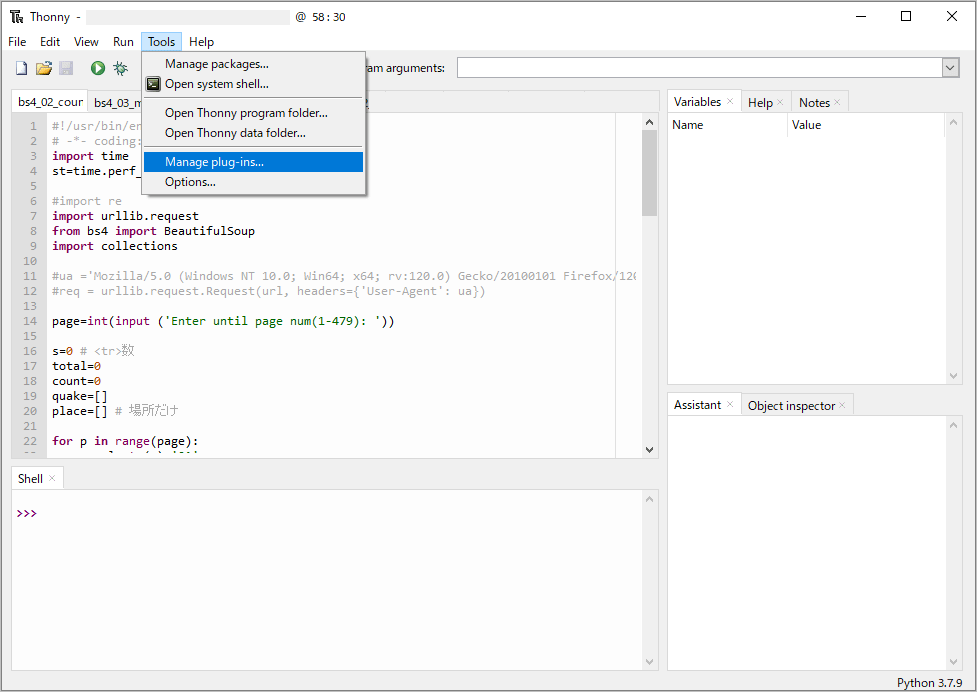
検索窓に「beautifulsoup4」を入力して、右の「Search on PyPi」をクリックします。
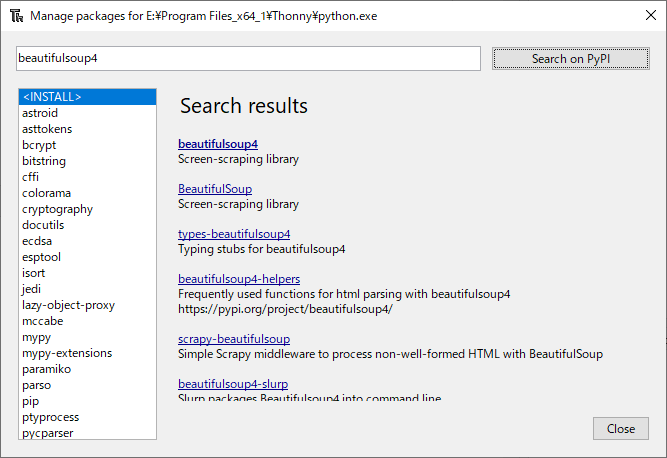
検索結果が表示されます。一番、上の「beautifulsoup4」を選択します。
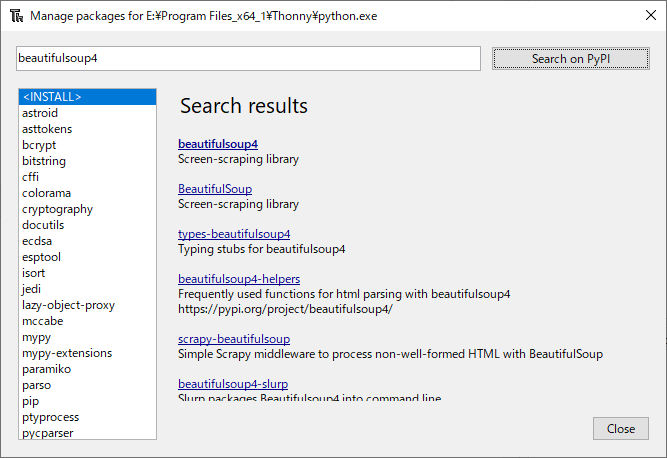
インストールされて、左の窓に「beautifulsoup4」が表示されます。
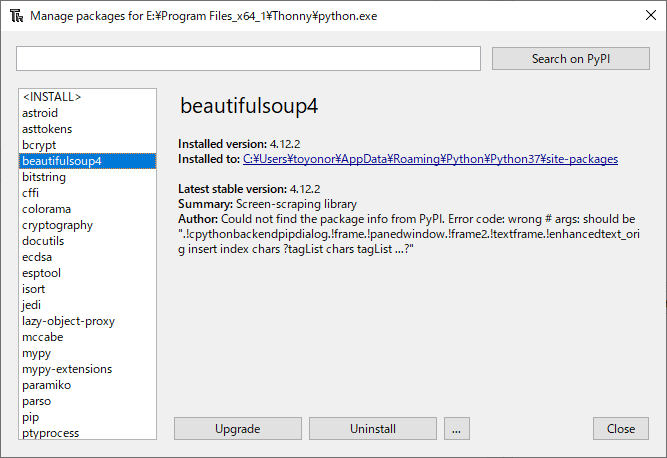
他にインストールして使えるものがあるようです。
xlm、html5の解析に使うパーサーlxml、html5libやCSS セレクターの実装ができるsoupsieveがあります。
ちなみに「soupsieve」の使い方は「https://facelessuser.github.io/soupsieve/」にあります。
3つインストールしましたが、使う機会はまだ無いです。
必要に応じて同様の方法でインストールすれば良いと思います。
スクレイピング
スクレイピングをやってみます。
Beautiful Soupを使ってウェブサイトから文章などを抽出してみます。
ヤフーニュースを例に、find()、find_all()、css.select()などを使って簡単なところ試してみようと思います。
例としてトピックスの「箱根駅伝 青学大が大会新で圧勝V」の文字データを取得してみます。
データを取得するにはBeautifulSoupで構造解析(パース)を行い、タグやCSSセレクタなどから取得したい場所を指定して情報を得ます。
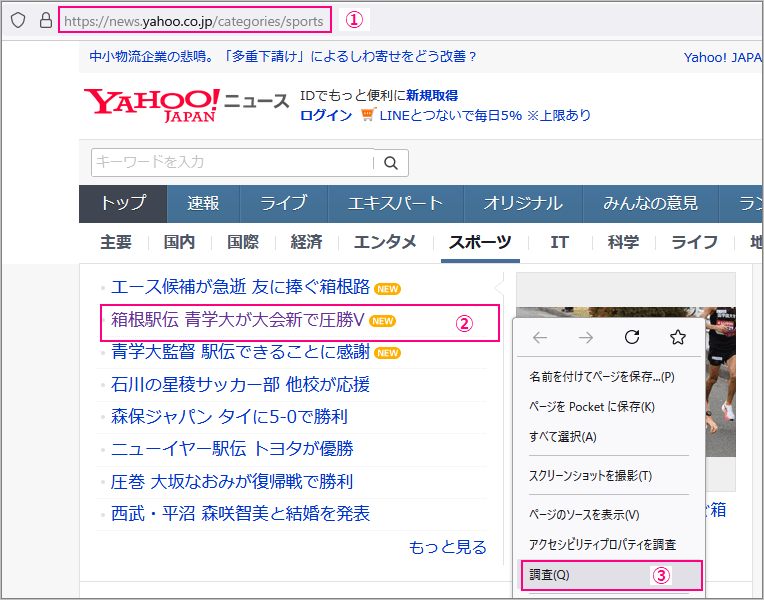
※Yahooニュースの画像のコピーです。
パース
サイト(html)のパース(soup)を取得するには、以下に記載した定型文のようにします。
import urllib.request
from bs4 import BeautifulSoup
url='https://news.yahoo.co.jp/categories/sports' # 上図①のサイトアドレス
req = urllib.request.Request(url)
html = urllib.request.urlopen(req)
soup = BeautifulSoup(html, "html.parser") #'html.parser'を使ってパースする
上図Yahooニュース画像に記した②のところで右クリック、ダイアログにある③調査を選択します。※ブラウザはFirefoxを使ってます。
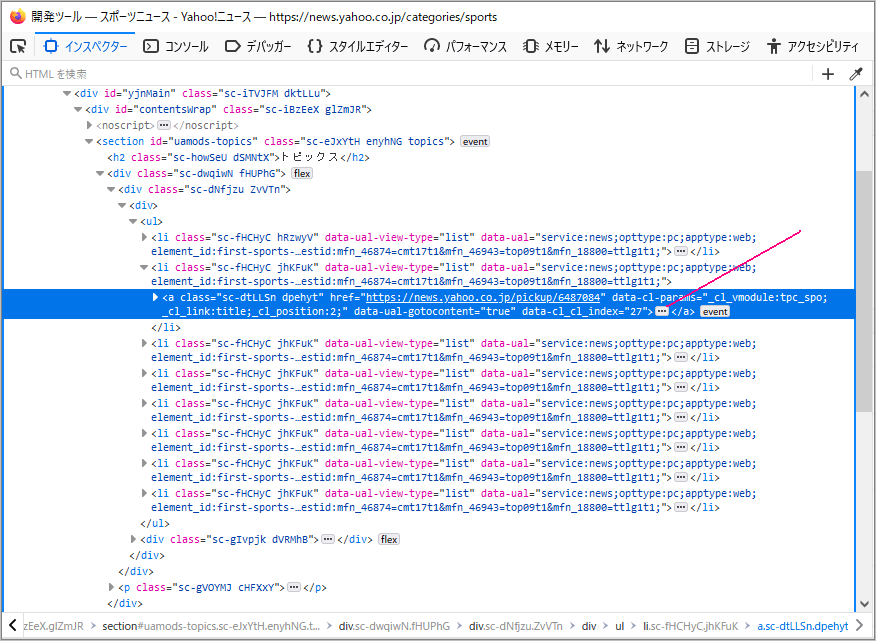
上図の赤線のところを展開すると、取得したい目的の場所であることが分かります。
<div class=”sc-dNfjzu ZvVTn”>で囲まれた、2番目の<li>内であることが分かります。
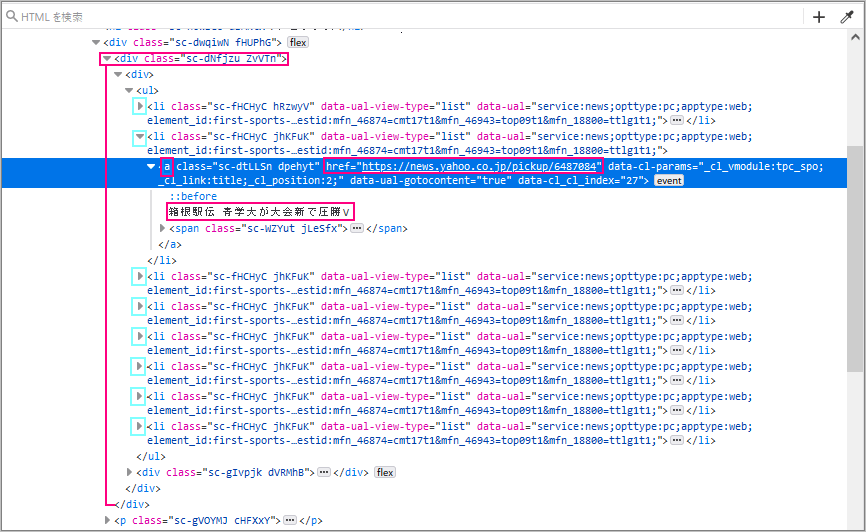
find()、find_all()
find()で探します。その内側に<li>が複数(トピックスの数)あるのでfind_all()で探します。
先のコードに以下を追加しました。
sc=soup.find(class_='sc-dNfjzu ZvVTn')
tgt=sc.find_all('li')
スクリプトを実行後、各値をThonnyのシェルで確認して見ます。
>>> type(soup)
<class 'bs4.BeautifulSoup'>
>>> type(sc)
<class 'bs4.element.Tag'>
>>> type(tgt)
<class 'bs4.element.ResultSet'>
>>> len(tgt)
8 #<li>の数 トピックスの数
目的の場所は<li>の2番目(tgt[1])になります。無事に抽出が出来ました。
>>> tgt[1]
<li class="sc-fHCHyC jhKFuK" data-ual="service:news;opttype:pc;apptype:web;element_id:
first-sports-topics-text;id_type:shannon_article;content_id:da6b1a62d
7195ea5cdc10841167bbfdafcb0126e;mtestid:mfn_46943=top09t2&mfn_46874=cmt17t1&
amp;mfn_18800=ttlg1t1;" data-ual-view-type="list"><a class="sc-dtLLSn
dpehyt" data-cl-params="_cl_vmodule:tpc_spo;_cl_link:title;_cl_position:3;" data-ual-go
tocontent="true" href="https://news.yahoo.co.jp/pickup/6487084">箱根駅伝 青学大が大会
新で圧勝V<span class="sc-WZYut jLeSfx"><span aria-label="NEW" class="sc-eirqVv XiyIJ"
role="img" type="NEW"></span></span></a></li>
タグの子要素を.contents調べられます。
>>> tgt[1].contents[0]
<a class="sc-dtLLSn dpehyt" data-cl-params="_cl_vmodule:tpc_spo;_cl_link:title;
_cl_position:3;" data-ual-gotocontent="true" href="https://news.yahoo.co.jp/pickup
/6487084">箱根駅伝 青学大が大会新で圧勝V<span class="sc-WZYut jLeSfx"><span aria-
label="NEW" class="sc-eirqVv XiyIJ" role="img" type="NEW"></span></span></a>
テキストを抽出してみます。
.get_text()
>>> tgt[1].get_text()
'箱根駅伝 青学大が大会新で圧勝V'
.string
>>> tgt[1].string #指定が不十分?空になった
.strings
>>> type(tgt[1].strings) #.stringsなら拾える場合もある
<class 'generator'>
>>> for s in tgt[1].strings:
print(s)
# 改行がある
箱根駅伝 青学大が大会新で圧勝
さらに<a>タグ部を抽出
>>> a=tgt[1].find('a')
>>> a
<a class="sc-dtLLSn dpehyt" data-cl-params="_cl_vmodule:tpc_spo;_cl_link:title;_cl_posi
tion:3;" data-ual-gotocontent="true" href="https://news.yahoo.co.jp/pickup/6487084">箱根
駅伝 青学大が大会新で圧勝V<span class="sc-WZYut jLeSfx"><span aria-label="NEW" cla
ss="sc-eirqVv XiyIJ" role="img" type="NEW"></span></span></a>
>>> type(a)
<class 'bs4.element.Tag'>
>>> len(a) # 要素数 以下のテキスト部と部
2
>>> cnt=0
>>> for tg in a:
print(cnt,tg)
cnt=cnt+1
0 箱根駅伝 青学大が大会新で圧勝V
1 <span class="sc-WZYut jLeSfx"><span aria-label="NEW" class="sc-eirqVv XiyIJ" role=
"img" type="NEW"></span></span>
<a>のテキスト部の取得
>>> a.get_text()
'箱根駅伝 青学大が大会新で圧勝V'
<a>のリンク部の取得
>>> a.get('href')
'https://news.yahoo.co.jp/pickup/6487084'
css.select
.selectで指定できます。
<a>タグ部を抽出
>>> aa=tgt[1].css.select('a')
>>> aa
[<a class="sc-dtLLSn dpehyt" data-cl-params="_cl_vmodule:tpc_spo;_cl_link:title;_cl_
position:3;" data-ual-gotocontent="true" href="https://news.yahoo.co.jp/pickup/6487084">
箱根駅伝 青学大が大会新で圧勝V<span class="sc-WZYut jLeSfx"><span aria-label="NEW"
class="sc-eirqVv XiyIJ" role="img" type="NEW"></span></span></a>]
>>> type(aa)
<class 'bs4.element.ResultSet'>
>>> aa=tgt[1].css.select('a[href]')
>>> aa
[<a class="sc-dtLLSn dpehyt" data-cl-params="_cl_vmodule:tpc_spo;_cl_link:title;_cl_
position:3;" data-ual-gotocontent="true" href="https://news.yahoo.co.jp/pickup/6487084">
箱根駅伝 青学大が大会新で圧勝V<span class="sc-WZYut jLeSfx"><span aria-label="NEW"
class="sc-eirqVv XiyIJ" role="img" type="NEW"></span></span></a>]
目的の場所は<li>の2番目
>>> aa=sc.css.select('li:nth-of-type(2)')
>>> aa
[<li class="sc-fHCHyC jhKFuK" data-ual="service:news;opttype:pc;apptype:web;element_id:
first-sports-topics-text;id_type:shannon_article;content_id:da6b1a62d7195ea5cdc10841167
bbfdafcb0126e;mtestid:mfn_46943=top09t2&mfn_46874=cmt17t1&mfn_18800=ttlg1t1;
" data-ual-view-type="list"><a class="sc-dtLLSn dpehyt" data-cl-params="_cl_vmodule:
tpc_spo;_cl_link:title;_cl_position:3;" data-ual-gotocontent="true" href="https://news.
yahoo.co.jp/pickup/6487084">箱根駅伝 青学大が大会新で圧勝V<span class="sc-WZYut jLeSfx"
><span aria-label="NEW" class="sc-eirqVv XiyIJ" role="img" type="NEW"></span><
/span></a></li>]
CSSセレクタで指定
青色の部分で右クリック「コピー>CSSセレクタ」を選択するとCSSセレクタがコピーできます。
コピペすると「li.sc-fHCHyC:nth-child(2) > a:nth-child(1)」でした。
.css.select(‘li.sc-fHCHyC:nth-child(2) > a:nth-child(1)’)
で指定できます。
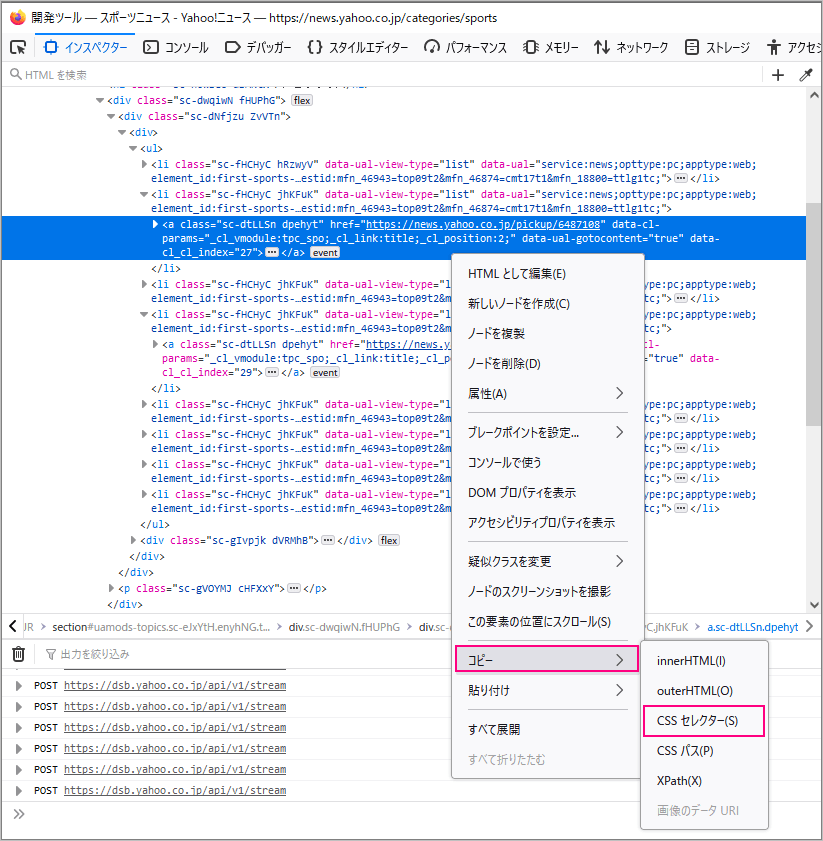
※記載時にはサイトが更新されいたので上図とは異なっています。
>>> c_sel='li.sc-fHCHyC:nth-child(2) > a:nth-child(1)'
>>> bb=soup.css.select(c_sel)
>>> bb
[<a class="sc-dtLLSn dpehyt" data-cl-params="_cl_vmodule:tpc_spo;_cl_link:title;_cl_
position:3;" data-ual-gotocontent="true" href="https://news.yahoo.co.jp/pickup/6487084">
箱根駅伝 青学大が大会新で圧勝V<span class="sc-WZYut jLeSfx"><span aria-label="NEW"
class="sc-eirqVv XiyIJ" role="img" type="NEW"></span></span></a>]
prettify
prettify()メソッドで構造解析を表示できます。綺麗に整理して出力してくれます。
Firefoxの「調査」の代わりにprettify()の出力でも調べることができると思います。
s=soup.prettify()
print(s)
データが長いとThonnyのShellでは見難いので以下のようにテキストファイルで保存して見れば良いと思います。
以下ではファイル名”bs4_soup.txt” で保存しています。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import urllib.request
from bs4 import BeautifulSoup
# parse
url='https://news.yahoo.co.jp/categories/sports'
req = urllib.request.Request(url)
html = urllib.request.urlopen(req)
soup = BeautifulSoup(html, "html.parser")
s=soup.prettify()
#print(s)
# write data to file
import sys
import codecs
file_path="bs4_soup.txt" #保存するファイル名
#sys.stdout
sys.stdout=open(file_path,"w") # 'w'上書 'a'追記
# error cp932 が発生する場合に必要
s=s.encode('cp932', "ignore")
s=s.decode('cp932')
print(s)
実行した後、bs4_soup.txtを確認すると下のようになっていました。
1行づつタグで仕切って見やすく整理されています。
<!DOCTYPE html>
<html lang="ja">
<head>
<title>
スポーツニュース - Yahoo!ニュース
</title>
省略
href="https://news.yahoo.co.jp/pickup/6487084">
箱根駅伝 青学大が大会新で圧勝V
</a>
省略
まとめ
BeautifulSoupを使って、簡単なスクレイピングが試せたと思います。
必要なデータをウェブサイトから抽出してデータ活用に便利かと思いました。