(v_17)PythonのフレームワークBottleを試す(3)

Bottleで始めるWEBアプリ
BeautifulSoupを使ってデータを抽出、整理して、そのデータをブラウザで閲覧する動作をBottleで作成してみようと思います。
具体的には記事(v_02)のBeautifulSoupでヤフー地震データを抽出しブラウザ表示します。
データ取得ページ数などの「入力表示ページ」と地震頻度順地域表示など「結果表示ページ」を作成します。その一連のweb動作をBottleで作成します。
※Pythonの開発環境はThonny、ブラウザはFirefoxを使用しています。
概要
データ取得ページ数など「入力表示ページ」と地震頻度順地域表示など「結果表示ページ」を作成します。
入力した値をBeautifulSoupを使った地震データ抽出のスクリプトに渡し、地震頻度データを結果表示ページへ返して、頻度順にテーブル表示します。
入力表示ページ
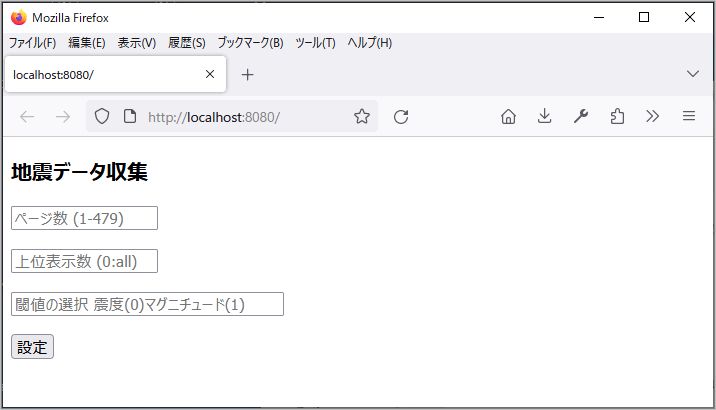
「入力表示ページ」は以下のようにしました。
取得するヤフー地震ページ数、頻度順表示上位数、震度かマグニチュードを選択
します。各値をPOSTします。
入力表示ページ(テンプレート quake_input_01.tpl)
quake_input_01.tpl
<!DOCTYPE html>
<html>
<h3>地震データ収集</h3>
<form method='POST'>
<p><input type='text' size='15' name='d_page' placeholder='ページ数 (1-479)'/><p>
<p><input type='text' size='15' name='d_rank' placeholder='上位表示数 (0:all)'/></p>
<p><input type='text' size='30' name='d_thre' placeholder='閾値の選択 震度(0)マグニ
チュード(1)'/></p>
<input type='submit' value='設定'/>
</form>
</html>
地震データ抽出
BeautifulSoupを使って、ヤフー地震データを抽出します。記事(v_02)のスクリプトを整理しています。詳細は記事(v_02)を参照ください。
pythonコードを「結果表示ページ」のHTMLに埋め込むとわかりにくいので、整理して以下のようにClass化しました。
bs4_quake_01b.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import urllib.request
from bs4 import BeautifulSoup
import collections
#Quake Class module
class Quake:
def __init__(self,pa=10,ra=10,th=0):
self.page=pa #取得ページ数
self.rank=ra #表示上位数
self.thre=th #閾値0:震度 1:Mag
#地震データ抽出
def q_Dat(self):
s=0 # <tr>数
total=0
count=0
quake=[]
place=[] # 場所だけ
for p in range(self.page):
p_val=str(p)+'01' #typhoon.yahoo page
url='https://typhoon.yahoo.co.jp/weather/jp/earthquake/list/?sort=
1&key=1&b='+p_val
req = urllib.request.Request(url)
html = urllib.request.urlopen(req)
soup = BeautifulSoup(html, "html.parser")
q_index=soup.find(id="eqhist")
# <tr>数
s=s+len(q_index.find_all('tr'))
for tr in q_index.find_all('tr'):
d_dat=[]
for td in tr.find_all('td'):
m_data=td.string
#print(m_data)
if m_data== None:
#None なら追加しない
continue
#日時、場所、マグニチュード、最大震度
#d_dat=[d_dat[0],d_dat[1],d_dat[2],d_dat[3]]
d_dat.append(m_data)
if d_dat==[]:
# 空なら追加しない 項目行が空
continue
total=total+1
#使用するデータの閾値
if self.thre==1:
# 場所d_dat[1] マグニチュー:d_dat[2] 震度:d_dat[3]
if d_dat[2]=='---' or d_dat[1]=='---':
continue
if float(d_dat[2]) < 1.5:
#マグニチュード<1.5 は除外 float(d_dat[2] < 1.5)
#震度'1'は除外 d_dat[3]=='1'
continue
else:
#震度が'1'と'---'、場所が'---'は除外する
#if d_dat[3]=='1' or d_dat[3]=='---' or d_dat[1]=='---':
if d_dat[3]=='---' or d_dat[1]=='---':
continue
count=count+1
if count==1:
d_st=d_dat[0] #期間抽出 最新の日時
place.append(d_dat[1]) #場所だけ
d_en=d_dat[0] #期間抽出 最古い日時
#import collections
#地震Counter
c=collections.Counter(place)
self.b=c.most_common() #出現回数が多い順
if self.thre==1:
#print('閾値はマグニチュード 1.5~')
msg='閾値はマグニチュード 1.5~'
else:
#print('閾値は震度 2~')
#print('閾値は震度 1~')
msg='閾値は震度 1~'
#データ数(total)、条件内使用データ数(count)
#print(f'Data:{count}/{total}')
self.mass=f'Data:{count}/{total}'
#
#期間抽出
#print(f'{d_st.split()[0]} ~ {d_en.split()[0]}') #収集データ期間
self.d_dur=f'{d_st.split()[0]} ~ {d_en.split()[0]}'
ss=''
if self.rank==0:
#print('全部表示')
self.ss=f'全部表示 '+msg
#全部データ
#print(self.b)
else:
#print(f'上位{self.rank}表示')
self.ss=f'上位{self.rank}表示 '+msg
#地震Counter全データを返す
def c_data(self):
return self.b
#データ数、ランク、文字列、データ期間を返す
def c_para(self):
return self.mass, self.rank, self.ss, self.d_dur
部分説明
Quake(ページ数,上位表示,閾値の種類)で初期化します。
メソッド
q_Dat()
ページ分の地震データ抽出
c_data()
地震Counter全データを返す
c_para()
データ数、ランク、文字列、データ期間を返す
Thonnyのshellで動作を確認しました。
>>> a=Quake(5,5,0) #インスタンス 5ページ分、上位5、閾値は震度
>>> a.q_Dat() #5ページ分の地震データ取得
>>> a.c_data() #地震全部データ
[('石川県能登地方', 93), ('豊後水道', 71), ('能登半島沖', 31), ('千葉県東方沖', 26),
('福島県沖', 17), ('宮城県沖', 12), ('奄美大島近海', 12),
省略
('相模湾', 1), ('愛知県西部', 1), ('北見地方', 1), ('日高地方東部', 1)]
>>> a.c_para() #地震データ取得条件、情報など
('Data:495/500', 5, '上位5表示 閾値は震度 1~', '2024年5月14日 ~ 2024年2月29日')
※Data:495/500 >> 使用データ/全データ 閾値などで弾いたデータは500-495=5ケ
結果表示ページ
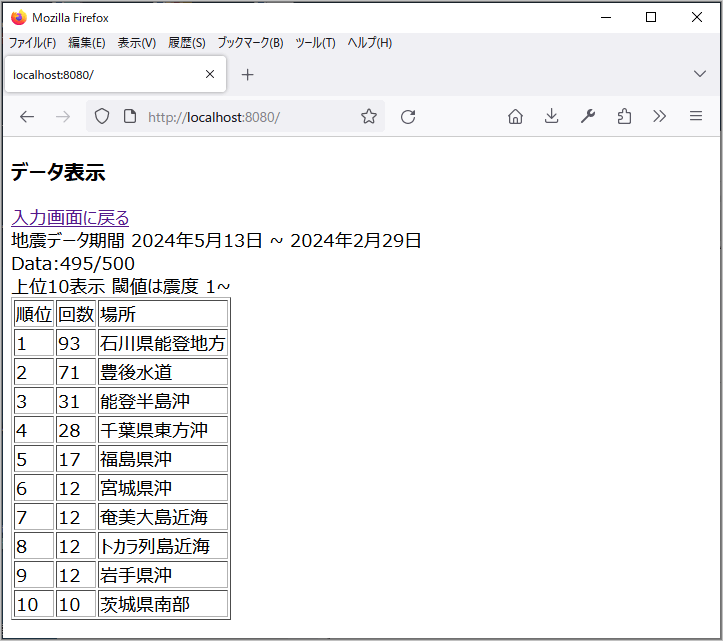
「入力表示ページ」は以下のようにしました。
BeautifulSoupを使って、ヤフー地震データを抽出した地震Counterデータを頻度順に表示しています。
結果表示ページ(テンプレート quake_list_01.tpl)
quake_list_01.tpl
<!DOCTYPE html>
<html>
<h3>データ表示</h3>
<a href='/'>入力画面に戻る</a><br>
<table border='1'>
<!-- % %end python code -->
<!-- data1 地震Counterデータ -->
<!-- data1 データ数、ランク、文字列、データ期間 -->
%a=data1
%b=data2
%rk=b[1]
地震データ期間 {{b[3]}}<br>
{{b[0]}}<br>
{{b[2]}}
<tr>
<td>順位</td>
<td>回数</td>
<td>場所</td>
</tr>
%cnt=1
%for i in range(rk):
<tr>
<td>{{cnt}}</td>
<td>{{a[i][1]}}</td>
<td>{{a[i][0]}}</td>
%cnt=cnt+1
%end
</table>
</html>
Bottle Web操作
Bottleを使って入力ページ、結果表示ページ、地震データ抽出を操作します。
スクリプトは以下のようにしました。
quake_web_01b.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
from bottle import route, run, template, request, redirect
#/quake ページ
@route('/', method=['GET','POST'])
@route('/quak', method=['GET','POST'])
def g_data():
if request.method=='POST':
page=request.POST.getunicode('d_page')
rank=request.POST.getunicode('d_rank')
thre=request.POST.getunicode('d_thre')
#入力漏れなら入力ページ表示
if page=='' or rank=='' or thre=='':
return template('d_input_01')
page=int(page)
rank=int(rank)
thre=int(thre)
#print(page,rank,thre)
#Beautifulsoup
from bs4_quake_01b import Quake
#Class Quake(取得ページ数,上位表示,閾値の種類 震度(0)マグニチュード(1))
quake=Quake(page,rank,thre)
quake.q_Dat()
#地震Counterデータ
data=quake.c_data()
#データ数、ランク、文字列、データ期間
para=quake.c_para()
#頻度順表示ページ
return template('quake_list_01',data1=data,data2=para)
#地震データ収集条件 設定 ページ
else:
return template('quake_input_01')
run(host='localhost', port=8080, debug=True)
部分説明
request.method==’POST’ならbs4_quake_01b.pyで地震データを頻度順に抽出し、
テンプレートquake_list_01.tplで結果ページを表示します。
‘POST’以外(’GET’)ならテンプレートquake_input_01.tplで入力ページを表示します。
動作確認
スクリプトの動作を確認します。
ブラウザを起動、「http://localhost:8080/」で入力ページが表示(GET)されます。
ページ数を5、上位表示を10、閾値を0で各値を入力し、「設定」ボタンを選択(POST)すると結果ページが表示されます。
ちなみに操作をした際のThonnyのshell部には以下のように出力されていました。
>>> %Run quake_web_01b.py
Bottle v0.13-dev server starting up (using WSGIRefServer())...
Listening on http://localhost:8080/
Hit Ctrl-C to quit.
C:\***\***\test\bottle.py:4088: DeprecationWarning: Flags not at the start of the
expression '\\{\\{((?:(?mx)( ' (truncated)
patterns = [re.compile(p % pattern_vars) for p in patterns]
127.0.0.1 - - [13/May/2024 12:16:41] "GET / HTTP/1.1" 200 435
127.0.0.1 - - [13/May/2024 12:17:04] "POST / HTTP/1.1" 200 1198
まとめ
Bottleを使ってBeautifulSoupで抽出した地震データをブラウザで表示するWeb動作の確認できたと思います。