(v_13)Selenium を使う

Seleniumで要素を抽出
先回の記事(v_12)ではBeautifulSoupとSeleniumを併用して要素を抽出しました。
今回はSeleniumだけで要素の抽出を試してみます。
※ThonnyでのSeleniumnインストールなどは記事(v_12)を参考にして下さい。
先回と同じSBI新生銀行サイト「https://www.sbishinseibank.co.jp/rate_list/yen.html?intcid=rate_list_txt06」の「円定期預金30」の金利を抽出してみます。
※Python開発環境はThonny、ブラウザはFirefoxを使用しています。
By
要素を探します。
モジュール class selenium.webdriver.common.byをインポートして
driver = webdriver.Firefox()
element = find_elements(By.CLASS_NAME,'block-h2')
のようにして要素を探します。
Byで指定できる項目は
CLASS_NAME ‘class name’
ID ‘id’
TAG_NAME ‘tag name’
NAME ‘name’
LINK_TEXT ‘link text’
PARTIAL_LINK_TEXT ‘partial link text’
XPATH ‘xpath’
CSS_SELECTOR ‘css selector’
があります。
CLASS_NAME TAG_NAME ID
先回と同じSBI新生銀行サイトの「円定期預金30」の金利を抽出してみます。
CLASS_NAME TAG_NAME IDの指定例です。
THonnyのShellで実行しながら確認して行きます。
>>> from selenium import webdriver
>>> from selenium.webdriver.common.by import By
>>> url='https://www.sbishinseibank.co.jp/rate_list/yen.html?intcid=rate_list_txt06'
>>> driver = webdriver.Firefox() #ブラウザFirefox起動
The version of firefox cannot be detected. Trying with latest driver version
>>> driver.get(url) # 以下の金利のページが表示されます。
※SBI新生銀行のサイトより
「パワーダイレクト円定期預金30」の金利の数値などを抽出してみます。
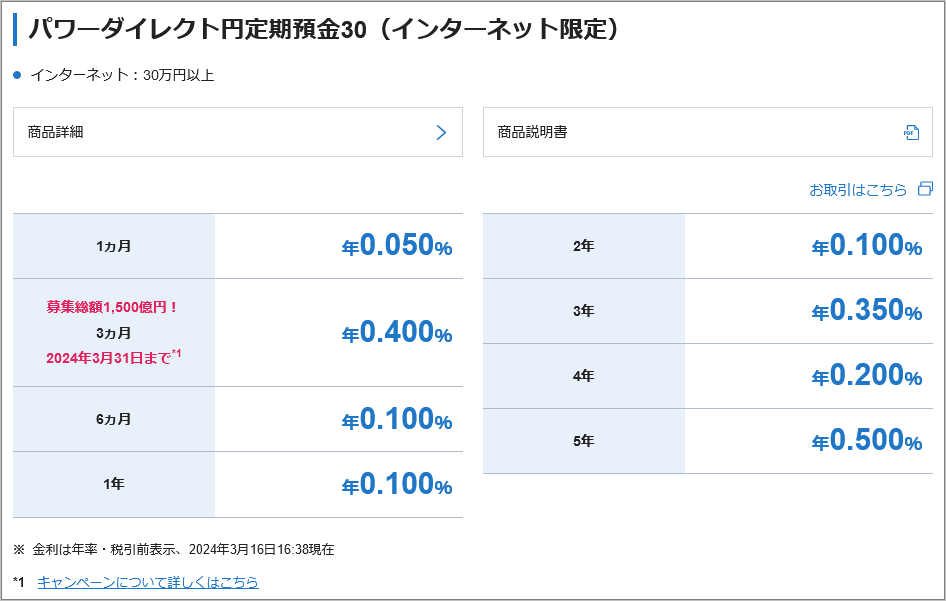
※SBI新生銀行のサイトより
Firefoxの「調査」で調べると「円定期預金30」の部分は以下の構造になっていました。
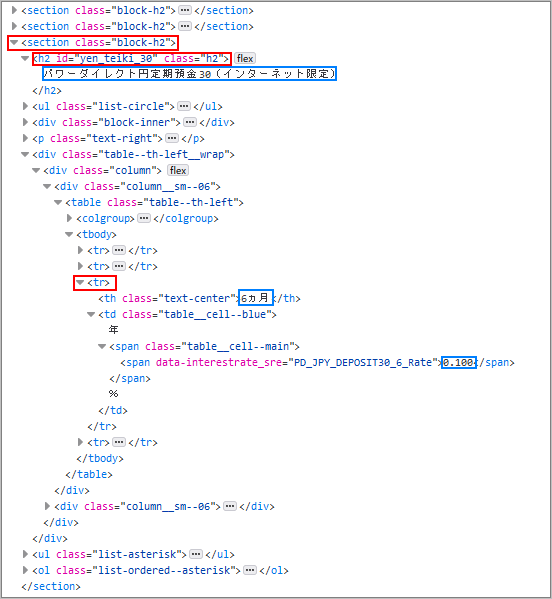
‘パワーダイレクト円定期預金30(インターネット限定)’を抽出してみます。
3つ目のclass=’block-h2’内、tag’h2’かid=’yen_teiki_30’で指定できそうです。
複数あるので「.find_elements」で探します。
>>> elem=driver.find_elements(By.CLASS_NAME,'block-h2')
3つ目なのでelem[2]の内のタグ’h2’内のテキストを抽出します。
>>> elem[2].find_element(By.TAG_NAME,'h2').text
'パワーダイレクト円定期預金30(インターネット限定)'
id=’yen_teiki_30’でも抽出できます。
>>> elem[2].find_element(By.ID,'yen_teiki_30').text
'パワーダイレクト円定期預金30(インターネット限定)'
金利は複数の’tr’タグ内にあります。複数なので「.find_elements」で探します。
>>> tr=elem[2].find_elements(By.TAG_NAME,'tr')
6ケ月定期の値を抽出する場合、3つめの’tr’内、’th’タグで「6ケ月」’td’タグで「年0.100%」が指定できそうです。
>>> tr[2].find_element(By.TAG_NAME,'th').text
'6ヵ月'
>>> tr[2].find_element(By.TAG_NAME,'td').text
'年0.100%'
ちなみに個別のタグで指定しなくても、以下のようにテキスト値を抽出できました。
>>> tr[2].text
'6ヵ月 年0.100%
複数の’tr’タグを同じように探すと全ての円定期預金30の値が抽出できそうです。
>>> for s in tr:
print(s.text)
1ヵ月 年0.050%
募集総額1,500億円!
3ヵ月
2024年3月31日まで*1 年0.400%
6ヵ月 年0.100%
1年 年0.100%
2年 年0.100%
3年 年0.350%
4年 年0.200%
5年 年0.500%
XPATH
XPATHを使って抽出してみます。
XPATHをFirefoxの「調査」で調べます。
‘パワーダイレクト円定期預金30(インターネット限定)’のXPATHはFirefoxの「調査>コピー>XPATH」を選択します。クリップボードにXPATHがコピーされます。
貼り付けると「//*[@id=”yen_teiki_30″]」が得られました。
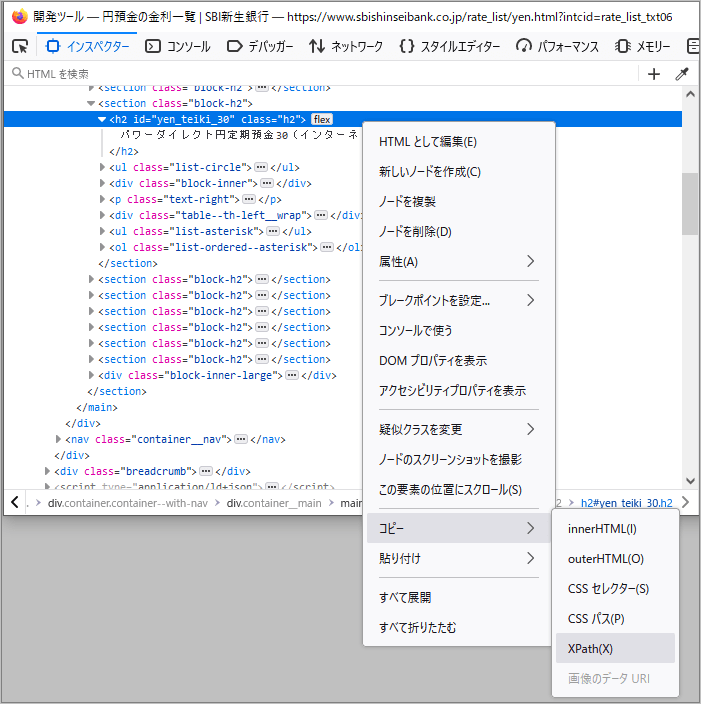
XPATHで探した結果です。
>>> driver.find_element(By.XPATH,'//*[@id="yen_teiki_30"]').text
'パワーダイレクト円定期預金30(インターネット限定)'
同じように「6ヵ月」のXPATHを調べると以下になりました。
XP=’/html/body/div[1]/div[1]/div/main/section/section[3]/div[2]/div/
div[1]/table/tbody/tr[3]/th’
XPATHで探した結果です。
>>> XP='/html/body/div[1]/div[1]/div/main/section/section[3]/div[2]/
div/div[1]/table/tbody/tr[3]/th'
>>> driver.find_element(By.XPATH,XP).text
'6ヵ月'
ちなみに以下のように分岐前を「//」に略しても指定できるようです。
>>> XP='//section[3]/div[2]/div/div[1]/table/tbody/tr[3]/th'
>>> driver.find_element(By.XPATH,XP).text
'6ヵ月'
同じように探すと金利値「0.100」は以下で指定できます。
>>> XP='//section[3]/div[2]/div/div[1]/table/tbody/tr[3]/td/span/span'
>>> driver.find_element(By.XPATH,XP).text
'0.100'
‘6ヵ月’は表左側の3番目なのでtr[3]になっているようなので期間はtr[1]~tr[4]で指定出来そうです。
表右側の「2年」のXPATHを調べるとdiv[2]になってます。
XP=’//section[3]/div[2]/div/div[2]/table/tbody/tr[1]/th’
表の右、左はdiv[1]、div[2]で指定出来そうです。以上を勘案して以下で探しました。
>>> for div in range(1,3):
for tr in range(1,5):
XP=f'//section[3]/div[2]/div/div[{div}]/table/tbody/tr[{tr}]/th'
kikan=driver.find_element(By.XPATH,XP)
XP=f'//section[3]/div[2]/div/div[{div}]/table/tbody/tr[{tr}]/td/span/span'
kinri=driver.find_element(By.XPATH,XP)
print(tr, kikan.text, kinri.text)
1 1ヵ月 0.050
2 募集総額1,500億円!
3ヵ月
2024年3月31日まで*1 0.400
3 6ヵ月 0.100
4 1年 0.100
1 2年 0.100
2 3年 0.350
3 4年 0.200
4 5年 0.500
スクリプト
以下は前述をまとめたスクリプトです。
Firefoxが表示されない-headlessで記載しています。
se_00_sinsei_04b.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# 新生銀行の金利サイト
url='https://www.sbishinseibank.co.jp/rate_list/yen.html?intcid=rate_list_txt06'
#Firefox WebDriverを作成
#-headless
options = webdriver.FirefoxOptions()
options.add_argument("-headless")
driver = webdriver.Firefox(options=options)
#driver = webdriver.Firefox() #optionなし
#最大待機時間
driver.implicitly_wait(10)
#サイトの表示
driver.get(url)
time.sleep(2)
##TAG_NAME CLASS_NAME
elem=driver.find_elements(By.CLASS_NAME,'block-h2')
#print(len(elem))
h2=elem[2].find_element(By.TAG_NAME,'h2')
print(h2.text)
#'パワーダイレクト円定期預金30(インターネット限定)'
tr=elem[2].find_elements(By.TAG_NAME,'tr')
for s in tr:
print(s.text)
print('\n')
## XPATH
a=driver.find_element(By.XPATH,'//*[@id="yen_teiki_30"]')
print(a.text)
# range(1,3)-> 1,2 range(1,5)-> 1,2,3,4
for div in range(1,3):
for tr in range(1,5):
XP=f'//section[3]/div[2]/div/div[{div}]/table/tbody/tr[{tr}]/th'
kikan=driver.find_element(By.XPATH,XP)
XP=f'//section[3]/div[2]/div/div[{div}]/table/tbody/tr[{tr}]/td/span/span'
kinri=driver.find_element(By.XPATH,XP)
#print(tr, kikan.text, kinri.text)
print(kikan.text, kinri.text)
driver.quit()
まとめ
Seleniumで要素の抽出を試してみました。
「class selenium.webdriver.common.by」を使ってCLASS_NAME、TAG_NAME、ID、XPATHで指定して要素を探すことが出来ました。