(v_12)Selenium / BeautifulSoup

BeautifulSoupとSeleniumを併用
SBI新生銀行のサイトで定期金利の確認することがたまにあります。
記事(v_01)でBeautifulSoupの使い方をかじったので金利データの抽出を試しました。
なぜかしら数値の抽出出来ませんでした。
※Python開発環境はThonny、ブラウザはFirefoxを使用しています。
BeautifulSoupで抽出
BeautifulSoupを使って以下の「円定期預金30」の部分の文字を抽出を試してみました。

※SBI新生銀行のサイトより
スクリプトは以下のようにしました。
se_00_sinsei_01b.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import urllib.request
from bs4 import BeautifulSoup
import time
# SBI新生銀行 円金利
sinsei='https://www.sbishinseibank.co.jp/rate_list/yen.html?intcid=rate_list_txt06'
url=sinsei
req = urllib.request.Request(url)
html = urllib.request.urlopen(req)
soup = BeautifulSoup(html, "html.parser")
time.sleep(1)
tgt=soup.find(id="yen_teiki_30") #パワーダイレクト円定期預金30
# 定期預金タイトル
print(tgt.string)
tgt=soup.find_all(class_="block-h2")
s_dat=tgt[2].get_text("|", strip=True)
s_dat=s_dat.split('|')
print(s_dat)
以下は実行、抽出した結果です。なぜかしら数値の抽出が出来ませんでした。
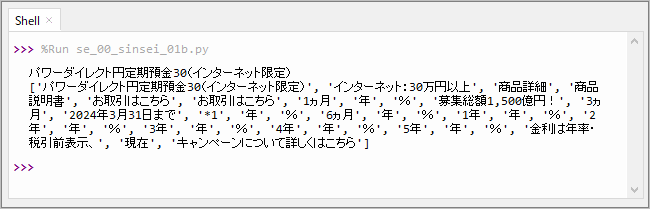
ページソースデータを確認
Firefoxでパワーダイレクト円定期預金30の2年、0.100%(2024.03.13現在)の部分を、ページソースデータを調べてみました。同じように数値が表示されていませんでした。
<tr>
<th class="text-center">2年</th>
<td class="table__cell--blue">
年
<span class="table__cell--main">
<span data-interestrate_sre="PD_JPY_DEPOSIT30_24_Rate"></span>
</span>
%</td>
</tr>
ちなみにFirefoxの「調査」で調べると以下のようにちゃんと数値あるのですが..。
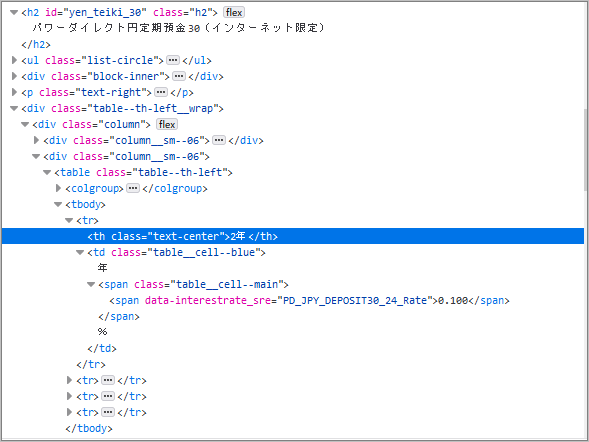
Selenium
何か抽出する方法がないのか調べてみました。
BeautifulSoup以外にSeleniumでもWEBスクレイピングが出来るそうです。
Seleniumでブラウザを操作するので動的なサイトでもスクレイピングが出来るそうです。
詳しくは分かりません。
※Selenium は Web ブラウザの操作を自動化するためのフレームワークです。
また、BeautifulSoupとSeleniumを併用することが出来るようです。
Seleniumでページのhtmlソースデータを取得し、BeautifulSoupで構造解析するような感じです。
この併用方法で抽出を試すことにしました。
■インストール
Seleniumをインストールします。
(BeautifulSoupは記事(v_01)で既にインストール済みです。インストールが必要なら以下と同方法でインストールできます。)
開発環境はThonnyを使用しています。そのためManage plug-insから簡単にBeautifulSoupをインストールできます。
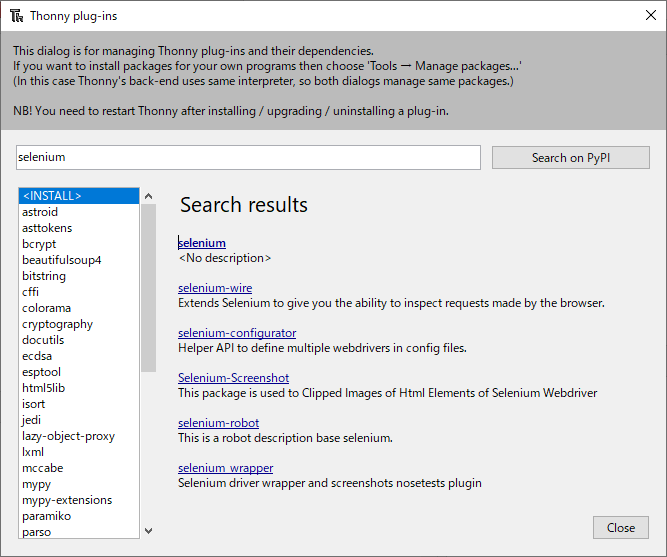
検索窓に「seleniumu」を入力して、右の「Search on PyPi」をクリックします。
検索結果が表示されます。一番、上の「seleniumu」を選択します。
「Install」をクリックします。
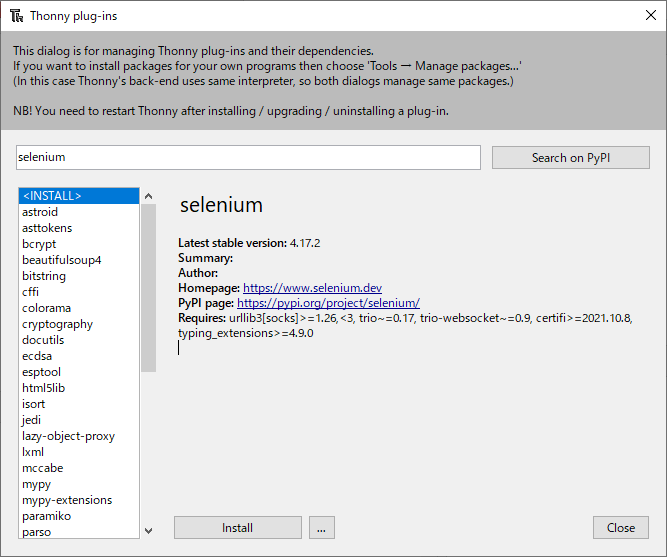
普段使いのブラウザにFirefoxを使っています。新規にFirefox起動用のgeckodriverを設置しなくても動いているように思います。そのためSeleniumをインストールだけで終わりです。(BeautifulSoupはインストール済みなので)
別途、geckodriverが必要な場合には「https://github.com/mozilla/geckodriver/releases」でダウンロードできます。
動作環境に応じたファイルをダウンロード、解凍を行い、実行ファイルをThonnyで作成したファイルを同階層に保存しておきます。
※試していませんが、普段使いのブラウザがChromeなら以下のスクリプト内のFirefoxの部分をChromに替えれば動作しそうに思います。(例:’FirefoxOptions’なら’ChromeOptions’)
SeleniumでFirefoxを起動
SeleniumでFirefoxを起動させてみます。
以下のスクリプトを実行してみました。
from selenium import webdriver
import time
# 新生銀行の金利サイト
url='https://www.sbishinseibank.co.jp/rate_list/yen.html?intcid=rate_list_txt06'
#Firefox WebDriverのインスタンスを作成
driver = webdriver.Firefox()
#最大待機時間を10秒にセット
driver.implicitly_wait(10)
#サイトを表示
driver.get(url)
実行結果
以下のようにFirefoxを起動してSBI新生銀行の金利サイトを表示できました。
ブラウザがリモート制御下にある表示がされていました。
ちなみに、Firefoxのヘルプから他のトラブルシューティングを選択すると状態が分かります。
実行ファイルは通常ブラウザで使っている実行ファイルと同じようです。
プロファイルは一時フォルダにその都度、新規で作成され、クローズすると消えるようです。

以下はThonnyのshellで確認しました。
>>> driver.name
'firefox'
>>> driver.current_url
'https://www.sbishinseibank.co.jp/rate_list/yen.html?intcid=rate_list_txt06'
>>> driver.title
'円預金の金利一覧 | SBI新生銀行'
>>> driver.quit() # Firefoxを終了
BeautifulSoupとSeleniumを併用
BeautifulSoupとSeleniumを併用して金利データを抽出します。
意外と簡単にできます。
Seleniumでページソースデータを取得し、
html=driver.page_source
そのデータをBeautifulSoupでパース(構造解析)して
soup = BeautifulSoup(html, “html.parser”)
金利データの部分を抽出します。
スクリプト
金利データの抽出が出来ればよく、サイトを画面に表示する必要はないので
#-headless
options = webdriver.FirefoxOptions()
options.add_argument(“-headless”)
driver = webdriver.Firefox(options=options)
にしています。
スクリプトは以下のようにしました。
se_00_sinsei_03.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
from selenium import webdriver
from bs4 import BeautifulSoup
import time
# 新生銀行の金利サイト
url='https://www.sbishinseibank.co.jp/rate_list/yen.html?intcid=rate_list_txt06'
#Firefox WebDriverのインスタンスを作成
#driver = webdriver.Firefox()
#-headless
options = webdriver.FirefoxOptions()
options.add_argument("-headless")
driver = webdriver.Firefox(options=options)
#最大待機時間を10秒にセット
driver.implicitly_wait(10)
#サイトの表示
driver.get(url)
time.sleep(2)
html=driver.page_source #ページソースデータを取得
driver.quit() #firefox close
print('firefox-headless..quit\n')
time.sleep(1)
#BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
time.sleep(1)
tgt=soup.find(id="yen_teiki_30") #パワーダイレクト円定期預金30
#定期預金タイトル
print(tgt.string)
#データ
tgt=soup.find_all(class_="block-h2")
s_dat=tgt[2].get_text("|", strip=True)
s_dat=s_dat.split('|')
print(s_dat)
実行結果
結果は以下のようになりました。金利の数値も抽出できています。
>>> %Run se_00_sinsei_03b.py
The version of firefox cannot be detected. Trying with latest driver version
firefox-headless..quit
パワーダイレクト円定期預金30(インターネット限定)
['パワーダイレクト円定期預金30(インターネット限定)', 'インターネット:30万円以上',
'商品詳細', '商品説明書', 'お取引はこちら', 'お取引はこちら', '1ヵ月', '年', '0.050',
'%', '募集総額1,500億円!', '3ヵ月', '2024年3月31日まで', '*1', '年', '0.400', '%',
'6ヵ月', '年', '0.100', '%', '1年', '年', '0.100', '%', '2年', '年', '0.100', '%',
'3年', '年', '0.350', '%', '4年', '年', '0.200', '%', '5年', '年', '0.500', '%',
'金利は年率・税引前表示、', '2024年3月14日20:36', '現在', 'キャンペーンについて詳しくはこちら']
データを見やすいように整理すれば良いのですが割愛します。
まとめ
BeautifulSoupだけでは抽出できなかったデータをSeleniumを併用することで抽出するできました。
機会があればSeleniumで抽出してみたいと思います。