(v_04)BeautifulSoup ヤフー 全国の天気

全国の天気を抽出
BeautifulSoupでヤフーの天気データを抽出しようと思います。
「全国の天気」データを抽出して表示したいと思います。
BeautifulSoupのインストールなどは記事(v_01)を参照して下さい。※開発環境はThonny、ブラウザはFirefoxを使用しています。
全国の天気
以下の図はヤフーの「全国の天気」のサイトです。
赤枠の文字列とマップ上の情報を抽出したいと思います。
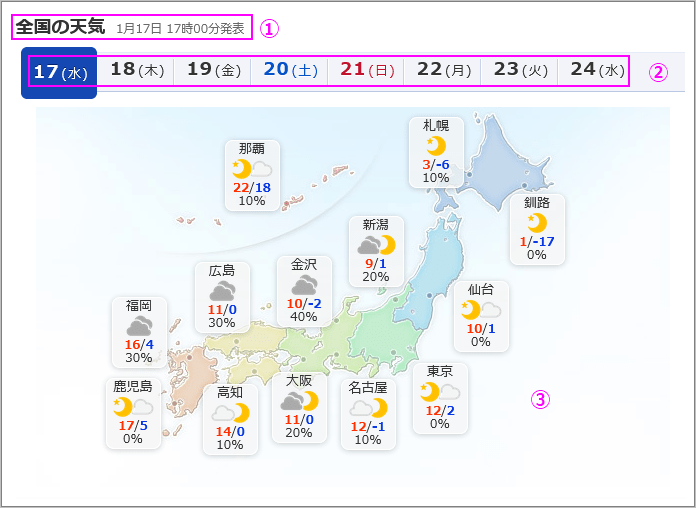
全国の天気のアドレスは
「https://weather.yahoo.co.jp/weather/?day=1」から来週「https://weather.yahoo.co.jp/weather/?day=8」まであります。「https://weather.yahoo.co.jp/weather/?」+「day=1~8」で選択できそうです。
とりあえずThonnyのShell部で行って行きます。「day=4」で以下のようにパースしました。
>>> import urllib.request
>>> from bs4 import BeautifulSoup
>>> url='https://weather.yahoo.co.jp/weather/?day=4'
>>> req = urllib.request.Request(url)
>>> html = urllib.request.urlopen(req)
>>> soup = BeautifulSoup(html, "html.parser")
タイトル①部
Firefoxでタグなどを調査するとid=’navHeader’で指定できそうです。
※「Firefoxで調査」については記事(v_01)を参照下さい。
>>> tgt=soup.find(id='navHeader')
>>> tgt
<div id="navHeader">
<h1 class="title">全国の天気</h1>
<span class="time">1月18日 8時00分発表</span>
</div>
テキスト部を抽出します。
>>> tgt.get_text(" -- ", strip=True)
'全国の天気 -- 1月18日 8時00分発表'
日にち選択部②
Firefoxで調査するとid=’navCal’、4番目(day=4)の’li’で指定できそうです。
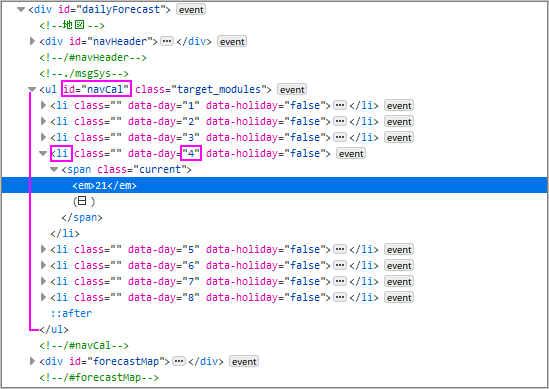
>>> tgt=soup.find(id='navCal')
>>> type(tgt)
<class 'bs4.element.ResultSet'>
>>> ugt=tgt.find_all('li')
>>> type(ugt)
<class 'bs4.element.ResultSet'>
>>> w_day=ugt[3] #4番目(day=4)
>>> w_day
<li data-day="4" data-holiday="false">
<span class="current">
<em>21</em>(日)
</span>
</li>
テキスト部を抽出します。
>>> w_day.get_text("日", strip=True)
'21日(日)'
ちなみにcss.selectを使うと”li[data-day=’4′]”で指定できます。
>>> yyy=tgt.css.select("li[data-day='4']")
>>> yyy
[<li data-day="4" data-holiday="false">
<span class="current">
<em>21</em>(日)
</span>
</li>]
>>> type(yyy)
<class 'bs4.element.ResultSet'>
テキスト部を抽出します。
>>> yyy[0].get_text("日", strip=True)
'21日(日)'
さらにCSSセレクトでも指定できます。
Firefoxの調査でCSSセレクトを調べると’#navCal > li:nth-child(4)’になっています。
>>> tgt=soup.css.select('#navCal > li:nth-child(4)')
>>> tgt
[<li data-day="4" data-holiday="false">
<span class="current">
<em>21</em>(日)
</span>
</li>]
>>> type(tgt)
<class 'bs4.element.ResultSet'>
同様にテキスト部を抽出します。
>>> tgt[0].get_text("日", strip=True)
'21日(日)'
マッフ③部
Firefoxで調査するとid=’map’、4番目(day=4)の’li’で指定できそうです。
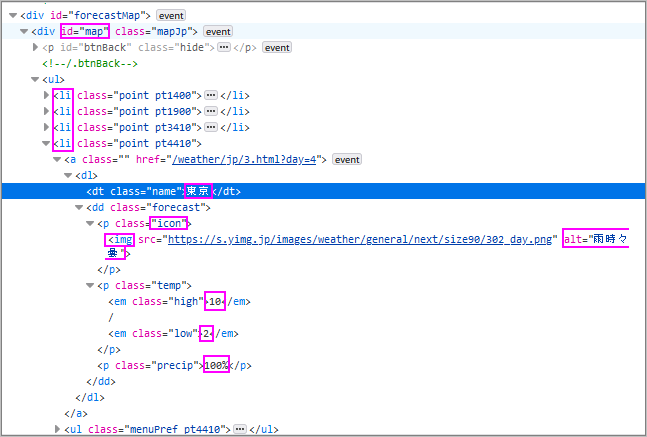
>>> tgt=soup.find(id='map')
>>> li=tgt.find_all('li')
>>> li[3].get_text("|", strip=True)
'東京|10|/|2|100%'
地名、気温、降水確率は抽出できましたが、天気が拾えません。
天気はアイコンで示されているためです。
そのため代替テキストのaltを抽出します。
‘img’タグの’alt’のテキストを拾います。
>>> img=li[3].find('img')
>>> img
<img alt="雨時々曇" src="https://s.yimg.jp/images/weather/general/next/size90/302_day.png"/>
>>> img.get('alt')
'雨時々曇'
リストデータの順番を地名、天気、気温、降水確率にします。
“|”で分離したリストにします。
>>> dat=li[3].get_text("|", strip=True)
>>> dat
'東京|10|/|2|100%'
>>> t_dat=li[3].get_text("|", strip=True)
>>> dat=t_dat.split('|')
>>> dat
['東京', '10', '/', '2', '100%']
‘/’は不要なので削除します。
>>> del dat[2]
>>> dat
['東京', '10', '2', '100%']
天気を2番目に挿入します。
>>> alt=img.get('alt')
>>> dat.insert(1,alt)
>>> dat
['東京', '雨時々曇', '10', '2', '100%']
スクリプト
以上をまとめスクリプトを以下のようにしました。
全国の天気の日付を指定できるようしています。
yzen_01b.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import urllib.request
from bs4 import BeautifulSoup
#import unicodedata
# 全国の天気 アドレス
ddy=int(input ('INPUT 全国の天気 本日(1)明日(2)~来週(8): '))
if ddy<1 or ddy>8:
ddy=1
# Yahoo weather url
u_url='https://weather.yahoo.co.jp/weather/?day=' # ~day=8
url=u_url+str(ddy) # +s_fund
req = urllib.request.Request(url)
html = urllib.request.urlopen(req)
soup = BeautifulSoup(html, "html.parser")
# 全国の天気 見出し
tgt=soup.find(id='navHeader')
dai=tgt.get_text(" -- ", strip=True)
print(dai) #全国の天気 -- 1月14日 14時00分発表
#日/曜日
#navCal > li:nth-child(4)
tgt=soup.find(id='navCal')
ugt=tgt.find_all('li')
w_day=ugt[(ddy-1)].get_text("日", strip=True)
print(f'{w_day}-----')
# weather
tgt=soup.find(id='map')
li=tgt.find_all('li')
#weather
wth=[]
for dl in li:
dat=[]
t_dat=dl.get_text("|", strip=True)
dat=t_dat.split('|') #['札幌', '3', '/', '-3', '80%']
del dat[2] #'/'を削除
# 天気アイコンは代替テキストaltを拾う
img=dl.find('img')
alt=img.get('alt') # get('alt')'雪'
dat.insert(1,alt) #['札幌', '雪', '3', '-3', '80%']
wth.append(dat)
# 表示
for i in wth:
print(f'{i[0]}\t {i[1]:8}\t {i[4]:>5}\t {i[2]:>4} /{i[3]:>3}')
実行結果
以下のような結果になりました。※ThonnyのShellに表示されます。
>>> %Run yzen_01b.py
INPUT 全国の天気 本日(1)明日(2)~来週(8): 4
全国の天気 -- 1月18日 15時00分発表
21日(日)-----
札幌 曇一時雪 60% -3 /-10
釧路 曇時々晴 40% -2 /-13
仙台 雨時々雪 90% 10 / 1
東京 雨時々曇 100% 10 / 2
名古屋 雨時々曇 100% 12 / 7
新潟 曇時々雨 90% 9 / 3
金沢 雨 90% 9 / 5
大阪 雨時々曇 100% 13 / 9
広島 曇一時雨 80% 14 / 8
高知 曇時々雨 90% 18 / 10
福岡 雨時々曇 90% 13 / 9
鹿児島 曇一時雨 70% 18 / 10
那覇 曇一時雨 60% 22 / 17
まとめ
BeautifulSoupを使ってヤフーの全国の天気データを抽出することができました。
天気アイコンの代替文字を抽出するところが少し難でした。