(v_02)BeautifulSoup ヤフー 地震

地震データの抽出
BeautifulSoupで実際に何かのデータ取得を練習してみようと思います。
ヤフーの地震データを整理して頻度順で地域を表示したいと思います。
BeautifulSoupのインストールなどは記事(v_01)を参照して下さい。
※開発環境はThonny、ブラウザはFirefoxを使用しています。
抽出データの指定
地震データは「https://typhoon.yahoo.co.jp/weather/jp/earthquake/list/」にあります。
パース(構文解析)データは以下で得ることができます。
この解析データ(soup)から抽出したい文字データを選択して行きます。
※ウェブサイトの更新等で画像のデータと記載が異なる場合があります。
ブラウザ(Firefox)で表示している地震データの上で右クリックして調査を選択し、地震データ表を指定た状態です。(ブラウザの調査については記事(v_01)を参考にしてください)
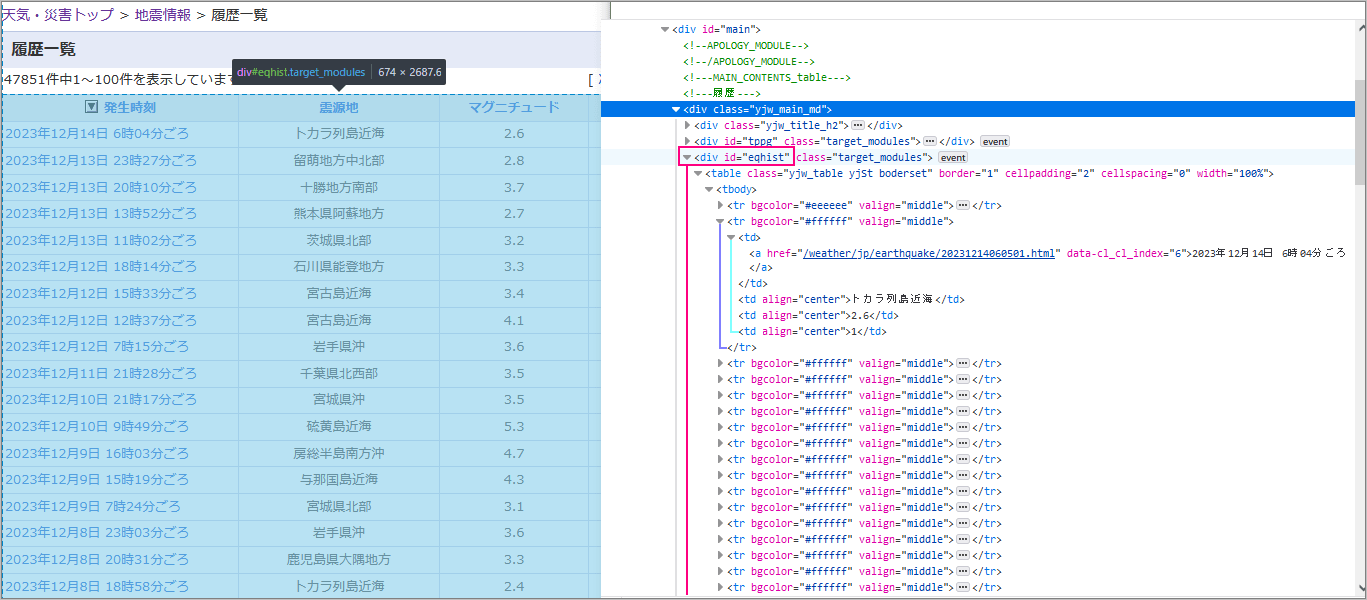
調査データから地震データはid=”eqhist”で大枠は指定できそうです。
<tr>タグは各行、<td>タグは各列(発生時刻、震源地、マグニチュード、最大震度)になっているようです。
解析データ(soup)のスクリプトを実行した後に、ThonnyのShellで確認しながら進めて行きます。
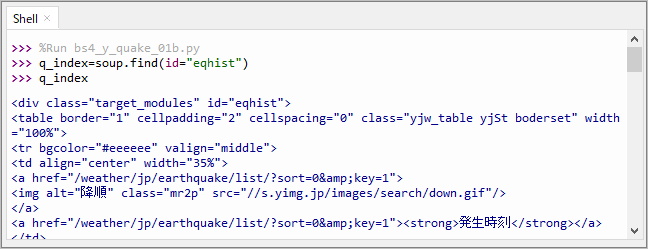
find(id=”eqhist”)で指定場所を確認します。以下のように地震データ表の場所が指定されていました。
>>> %Run bs4_y_quake_01b.py
>>> q_index=soup.find(id="eqhist")
>>> q_index
<div class="target_modules" id="eqhist">
<table border="1" cellpadding="2" cellspacing="0" class="yjw_table
yjSt boderset" width="100%">
省略
地震データは<td>タグにあるので、find_all(‘td’)で調べてみます。
>>> for td in q_index.find_all('td'):
print(td.string)
None
None
None
None
2023年12月16日 14時09分ごろ
根室地方北部
2.7
1
2023年12月16日 11時44分ごろ
岐阜県美濃中西部
3.9
2
省略
Noneは地震データの項目名の行で階層が違うので.stringで文字列「発生時刻、震源地、マグニチュード、最大震度」が抽出できていません。
先の調査したデータを見ると各行の<tr>タグ内に地震データ<td>タグが4つ(発生時刻、震源地、マグニチュード、最大震度)あります。タグに則してデータ抽出を考えると以下になります。表示結果は同じです。
>>> for tr in q_index.find_all('tr'):
for td in tr.find_all('td'):
print(td.string)
None
None
None
None
2023年12月16日 14時09分ごろ
根室地方北部
2.7
1
2023年12月16日 11時44分ごろ
岐阜県美濃中西部
3.9
2
省略
ちなみに .stringの部分を.get_text(”,strip=True)にすると、以下のようにNoneの部分も拾えます。
>>> for tr in q_index.find_all('tr'):
for td in tr.find_all('td'):
print(td.get_text('',strip=True))
発生時刻
震源地
マグニチュード
最大震度
2023年12月16日 14時09分ごろ
根室地方北部
2.7
1
2023年12月16日 11時44分ごろ
岐阜県美濃中西部
3.9
2
省略
以上をまとめます。None部はデータ抽出を除外しています。
bs4_01_q_02.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import urllib.request
from bs4 import BeautifulSoup
url='https://typhoon.yahoo.co.jp/weather/jp/earthquake/list/'
req = urllib.request.Request(url)
html = urllib.request.urlopen(req)
soup = BeautifulSoup(html, "html.parser")
q_index=soup.find(id="eqhist")
quake=[] #地震データのリスト
for tr in q_index.find_all('tr'):
d_dat=[] #地震データ
for td in tr.find_all('td'):
m_data=td.string
if m_data== None:
#None なら追加しない
continue
d_dat.append(m_data)
if d_dat==[]:
# 空なら追加しない
continue
quake.append(d_dat)
print(quake)
実行結果
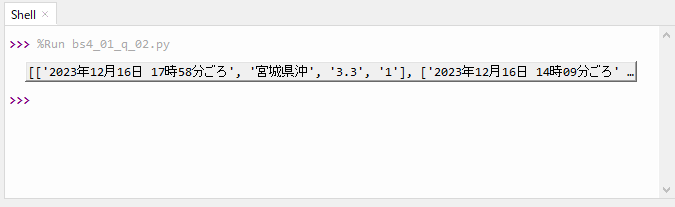
結果データを展開すると地震データの1ページ分が取得できています。
地震データの抽出
複数ページの地震データを抽出して、震源地の頻度が多い順に並べてみようと思います。
最大震度の値を閾値にして震源地名を取得してリストデータ化し、震源地の出現回数順に並べ替えます。
スクリプトは以下のようにしました。
bs4_02_count_02.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import urllib.request
from bs4 import BeautifulSoup
import collections
# 地震データ収集ページ数
page=int(input ('Enter page(1-50): ')) #ページ数の入力 50までに制限
if page>50:
page=50
s=0 #<tr>数 行数
total=0 # 空データ(項目名)を除いたデータ数
count=0 # 閾値を超えデータ
place=[] # 場所だけ
#ページ数分の地震場所リストを作成する
for p in range(page):
p_val=str(p)+'01'
url='https://typhoon.yahoo.co.jp/weather/jp/earthquake/list/?sort=1&key=1&b='+p_val
req = urllib.request.Request(url)
html = urllib.request.urlopen(req)
soup = BeautifulSoup(html, "html.parser")
#print(soup.prettify())
q_index=soup.find(id="eqhist")
#<tr>数 行数
s=s+len(q_index.find_all('tr'))
for tr in q_index.find_all('tr'):
d_dat=[] #[日時、場所、マグニチュード、最大震度]
for td in tr.find_all('td'):
m_data=td.string # 個別データ
if m_data== None:
#None なら追加しない
continue
#日時、場所、マグニチュード、最大震度
#d_dat=[d_dat[0],d_dat[1],d_dat[2],d_dat[3]]
d_dat.append(m_data)
if d_dat==[]:
# 空なら追加しない 項目名の行は空
continue
total=total+1 #空以外のデータ数
#震度が'1'と'---'、場所が'---'は除外する 実質震度2~
if d_dat[3]=='1' or d_dat[3]=='---' or d_dat[1]=='---':
continue
count=count+1 #条件内の実データ数
if count==1:
d_st=d_dat[0] #最新の日時(最初のデータ)
place.append(d_dat[1]) #場所だけのリストデータ
d_en=d_dat[0] #最古い日時(最後のデータ)
#作成した地震場所リストを頻度データにする
#import collections
c=collections.Counter(place) # 場所、頻度 Counterオブジェクト
c.most_common() # タプルのリスト
# 表示不要ならコメントアウト
print(c)
print(s,total,count) #処理数(tr)、データ数、条件内データ数
print('Rank5=', c.most_common()[0:5]) #上位5ピックアップ
print(f'{d_st.split()[0]} ~ {d_en.split()[0]}') #収集データ期間
部分説明
地震データのアドレス
地震データの1ページ目は先に記載したように「https://typhoon.yahoo.co.jp/weather/jp/earthquake/list/」なのですが、2ページ目をクリックして表示させた後に1ページ目をクリックすると「https://typhoon.yahoo.co.jp/weather/jp/earthquake/list/?sort=1&key=1&b=1」になります。

※Yahooの地震ページです。
2ページ目
「https://typhoon.yahoo.co.jp/weather/jp/earthquake/list/?sort=1&key=1&b=101」
3ページ目
「https://typhoon.yahoo.co.jp/weather/jp/earthquake/list/?sort=1&key=1&b=201」
のようになっているので、地震データのアドレスは以下であらわせます。
p_val=str(ページ番号-1)+’01’
url=’https://typhoon.yahoo.co.jp/weather/jp/earthquake/list/?sort=1&key=1&b=’+p_val
※スクリプトではrange(page)なので、実質(ページ番号-1)と同じになります。
にしています。
地震場所リスト
前述のデータ抽出のスクリプトを元に地震場所をリストデータ化しています。
頻度データ化
collections.Counter
collections.Counter()を使ってキーに震源地、値に出現回数の形のCounterオブジェクトを作成します。
その後にmost_common()で(震源地, 出現回数)という型のタプルを出現回数順に並べたリストにしています。
実行結果
実行結果は以下になりました。地震データは2ページ分です。
2023年12月23日 ~ 2023年11月10日の期間のデータ数は200、震度’1′,’—‘以外の使用データ数は63でした。そのうち上位5を再表示しています。
>>> %Run bs4_02_count_02.py
Enter until page num(1-479): 2
Counter({'トカラ列島近海': 5, '千葉県東方沖': 4, '宮城県沖': 3, '福島県沖': 3, '岩手県沖': 2,
'宮城県北部': 2, '茨城県南部': 2, '茨城県北部': 2, '奄美大島近海': 2, '熊本県熊本地方': 2,
'新島・神津島近海': 2, '鹿児島湾': 2, '橘湾': 1, '長野県中部': 1, '大分県中部': 1, '栃木県南部': 1,
'山口県北西沖': 1, '岐阜県美濃中西部': 1, '豊後水道': 1, '日高地方中部': 1, '十勝地方南部': 1,
'熊本県阿蘇地方': 1, '房総半島南方沖': 1, '福島県会津': 1, '千葉県北東部': 1, '岩手県沿岸北部': 1,
'新潟県中越地方': 1, '富山湾': 1, '相模湾': 1, '岩手県内陸北部': 1, '熊本県天草・芦北地方': 1,
'国後島付近': 1, '沖縄本島北西沖': 1, '与那国島近海': 1, '茨城県沖': 1, '山形県最上地方': 1,
'薩摩半島西方沖': 1, '青森県東方沖': 1, '徳島県南部': 1, '愛媛県東予': 1, '根室半島南東沖': 1,
'鹿児島県大隅地方': 1, '京都府北部': 1, '千島列島': 1})
202 200 63 #行数、データ数、条件内のデータ数(使用データ)
Rank5= [('トカラ列島近海', 5), ('千葉県東方沖', 4), ('宮城県沖', 3), ('福島県沖', 3),
('岩手県沖', 2)]
2023年12月23日 ~ 2023年11月10日
ちなみに、記載時における50ページ分(2024年1月6日 ~ 2021年12月4日)の地震頻度を調べると以下のようになりました。
2024.1.1の能登半島での地震災害が入っています。上位10を表示しています。
>>> %Run bs4_02_count_02.py
Enter page(1-479): 50
5050 5000 1850
Rank10= [('石川県能登地方', 318), ('トカラ列島近海', 267), ('福島県沖', 129), ('能登半島沖', 100),
('宮城県沖', 70), ('茨城県南部', 38), ('岩手県沖', 36), ('沖縄本島北西沖', 34), ('茨城県沖', 33),
('千葉県東方沖', 32)]
2024年1月6日 ~ 2021年12月4日
まとめ
BeautifulSoupを使ってYahooの地震データを抽出し整理することができました。
追記
当方は南海トラフ地震がきたら・・と怯えています。
そのため地震の頻度を調べようと昨年末にスクリプトを作成していました。
まさか元旦に能登で大地震が発生するとは夢にも思いませんでした。
知り合いは無事でしたが実家は半壊になったそうです。
早く復旧することを願っています。