2024/03/29
(v_09)Python メール件名と差出人

SubjectとFrom
Pythonでいろいろやって見たことを記載しています。※開発環境はThonnyを使用しています。
記事(v_07)と記事(v_08)を応用してメール件名(Subject)と差出人(From)だけ表示して見ようと思います。
スクリプト
スクリプトは以下のようにしました。
mime_subject_from_01b.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import getpass, poplib
import base64
import quopri
# MIME形式を変換
def m_chn(bytes_msg):
s=bytes_msg.decode() #bytes->moji
sp=s.split(' ') #'_'で分離 正当なやり方だろうと思う リスト化
n=len(sp) #分離した数
bun='' #変換した文字列
ss=[] #'?='付き部分
for i in sp:
if '?=' in i: #'?='がある項だけのリストにする
ss.append(i)
else:
bun=bun + i # '?='のついていない subject:などの文字列
dat=[] #[[moji-code, encode, bytes-data],[ ]]に分離する
for j in ss:
j=j.replace('?=','') #'?='を消去
j=j.replace('=?','') #'=?'を消去 ==?はあり得るようなので後で削除
j=j.split('?') #'?'で分離
dat.append(j) # 以下のような形式になる
##print('dat=',dat) #[[moji-code, encode, bytes-moji-data],[ -- ]]
k=len(dat)
for i in range(k):
#charset(文字コード)
chset=dat[i][0] # charset(utf-8, iso-2022-jp, ascii)
#Content-Transfer-Encoding
ctenc=dat[i][1] # moji-encode(base64, quoted-printable non)
#文
msg=dat[i][2] # bytes-moji-data(massage)
##print(msg)
if 'B' in ctenc.upper():
cte='base64'
b = base64.b64decode(msg) #b bytedata 文
##print('base64 decode-data',b)
elif 'Q' in ctenc.upper():
cte='quoted-printable'
msg=msg.replace(b'==',b'=')
b = quopri.decodestring(msg)
##print('quoted decode-data',b)
else:
cte='non'
b = msg
##print('non decode-data',b)
line=b.decode(chset, "ignore") #chset=dat[i][0]
#line=b.decode(chset, "replace")
bun=bun + line # つなぐ
print(bun)
return bun
# 指定した文字列(b_moji)を含む行をリストで返す
def chk_moji(b_msg, b_moji):
m=len(b_msg) # b_msg bytes文字列データ
gyo=[] # 指定文字を含む行のリスト
# moji のある行を探して行番号を返す
for i in range(m):
moj=b_moji # bytes文字
# mojiが含まれているか調べる
if moj in b_msg[i]:
gyo.append(i)
return gyo # 行番号リスト
# main---------------------------------------------------
#user data
udat=[' ']*3 #['POP server','user_account', 'Passwords']
udat[0]='pop.****.**.***'
udat[1]='*****@*****.ne.jp'
udat[2]='**********'
#M=poplib.POP3(udat[0], port=110, timeout=10) #udat[0]:'POP server' port=110
M=poplib.POP3_SSL(udat[0], port=995, timeout=10) #udat[0]:'POP server' port=995
M.user(udat[1]) #udat[1]:'user_account'
M.pass_(udat[2]) #udat[2]:'Passwords'
rs=M.list() #(response, ['mesg_num octets', ...], octets)
print('M.List=',rs)
print('')
n_rs=len(rs[1]) #メール数
for which in range(1,n_rs+1):
g_msg=M.retr(which) #(response, ['line', ...], octets)
msg=g_msg[1] # ['line', ...]
m=len(msg) # 行数
s_num=chk_moji(msg, b'Subject: ') #Subject: =?
f_num=chk_moji(msg, b'From: ') #From: =?
#b'Subject:' b'From:' 最初に見つかった行を使う前提にしている
ss=[s_num[0]]
ff=f_num[0]
# Subjectが複数行の場合の処理
for i in range(s_num[0]+1, m):
if b':' not in msg[i]:
ss.append(i)
else:
break
s_msg=b'' # s_msg MIMEデコードする文字列データ
for j in ss:
s_msg=s_msg + msg[j]
# 受信メール番号、件名、差出人の表示
print(f'which({which})')
#'Subject:'
m_chn(s_msg)
#'From:'
m_chn(msg[ff])
print('')
# sighn off
M.quit()
部分説明
■m_chn(bytes_msg)
bytes_msgをbase64やquotedでデコードし、charset(文字コード)でデコードします。
記事(v_08)とほぼ同じです。
■chk_moji(b_msg, b_moji)
b_mojiを含むb_msgの行番号をリスト形式で返します。
メール数などを取得(記事(v_07)参照)して、
g_msg=M.retr(which) # which:メール番号
受信メールデータ内をchk_moji() で「b’Subject:’、b’From:’」の含んでいる行番号をリストデータを返します。
このリストデータをm_chn(bytes_msg)で変換するような感じです。
# Subjectが複数行の場合の処理
以下のような複数行になっていることがあったので、次にb’:’を含む行の前までを追加しています。
※下の例では63行から次にb’:’を含む66行b’References:の前65行までの[63,64,65]がリストデータになります。
63 b'Subject: =?UTF-8?B?RndkOiDpmL/ljZfluIIg44GL44KJIOOBv+OBl+OBvuOChOODtOOCpw==?='
64 b' =?UTF-8?B?44Or44OHIOWFq+adn+W6lyDjgb7jgafvvIjniZvpqqjjg6njg7zjg6Hjg7Mg5a+M?='
65 b' =?UTF-8?B?44KT44KE44CB5rGf5bO25aSn5qmLIOe1jOeUse+8ieOBruODq+ODvOODiA==?='
66 b'References: <qWidKHnJU3QC4Krn4HAM7A@notifications.google.com>'
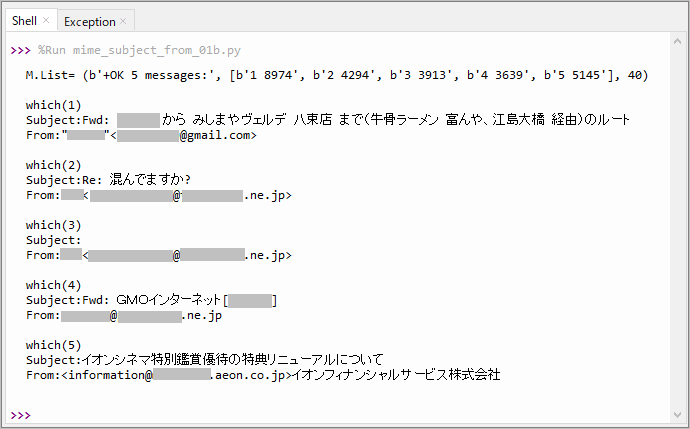
実行結果
実行結果は以下のようになりました。
受信メールの件数は5件です。各件名と差出人が表示されています。メール(5)の件名は先のように[63,64,65]が連なった「Subject:イオンシネマ特別鑑賞優待の特典リニューアルについて」になっています。
まとめ
メール件名と差出人のリストを表示することができました。
不要メールの削除の判断に使えるかも知れません。